
Good customer research is slow for a reason: you’re collecting stories, reconciling contradictions, and converting them into decisions. AI can’t replace that judgment—but it can shorten the distance from raw signal to useful insight. Used well, it automates the busywork (recruiting emails, note-taking, clean transcripts, clustering quotes) and enforces consistency (rubrics, templates, evidence links). Used poorly, it fabricates facts or mashes everyone into the same average persona.
This playbook shows a production-safe way to run interviews, summaries, and insight mining with AI—without losing rigor or ethics.
What AI should (and shouldn’t) do in research
Great at
- Scheduling and screening logistics; deduping candidates.
- Live note-taking with timestamps, action items, and glossary normalization.
- Transcript cleanup, speaker diarization, and PII redaction.
- Structured summaries to a rubric (JTBD, pains, triggers, objections, quotes).
- Pre-coding and clustering to seed affinity maps; building a searchable quote bank.
Keep human
- Framing the research question and sample frame.
- Asking follow-ups, managing silence, reading non-verbals.
- Reconciling conflicting evidence and calling the non-obvious insight.
- Deciding what you’ll change in the product, offer, or messaging.
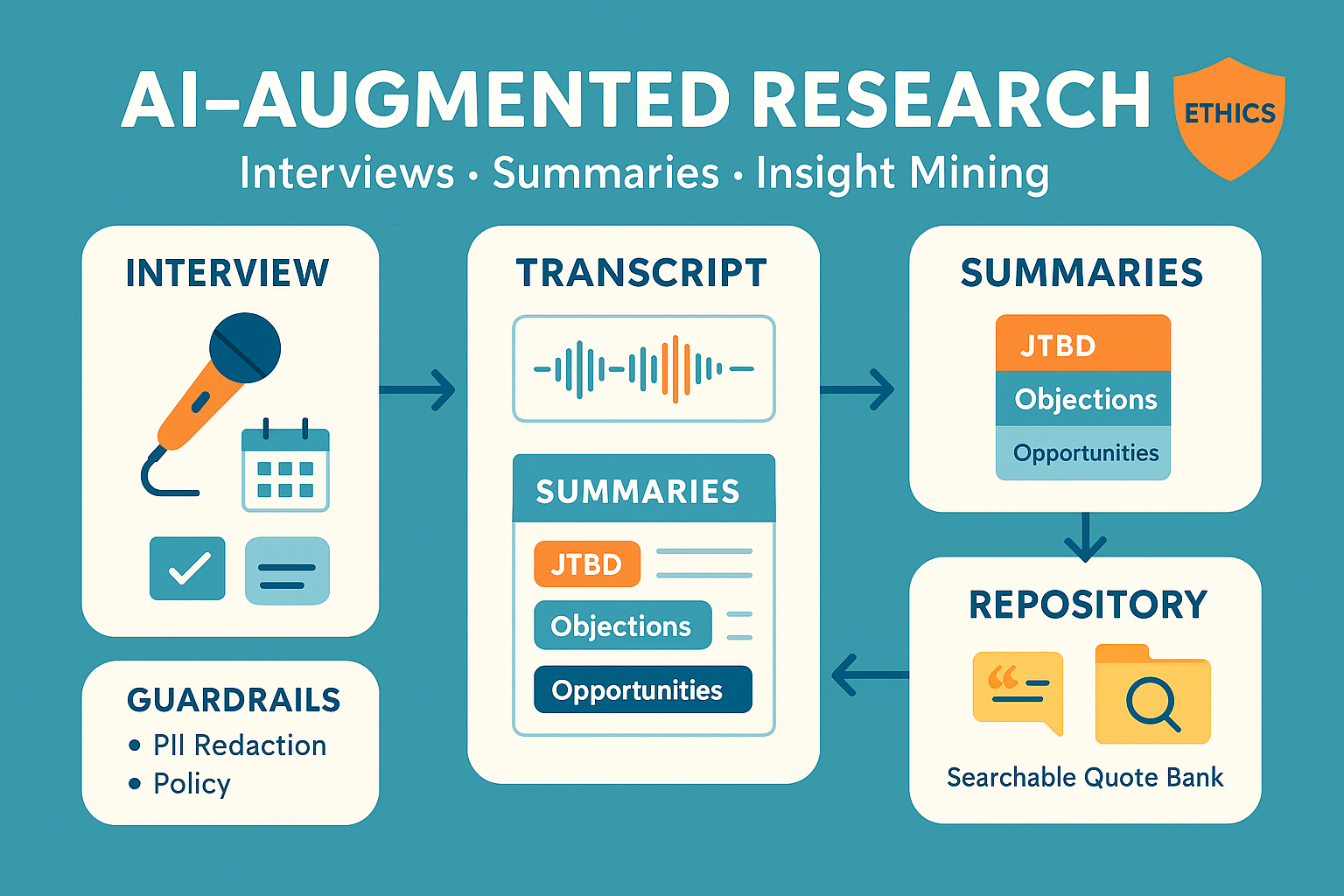
Reference workflow (end-to-end)
- Recruit & consent → screeners, invites, consent captured and stored.
- Interview → human-led conversation; AI takes structured notes (no claims or interpretations).
- Transcribe & clean → diarize speakers, redact PII, normalize terms (your glossary).
- Summarize to rubric → auto-create artifacts: JTBD sheet, objections list, highlights with timestamps, opportunity areas.
- Insight mining → AI pre-codes; researcher reviews, merges, and labels themes; produce Insight Cards with evidence.
- Archive → quotes, clips, and decisions pushed to a searchable research repository with tags/links.
- Report & act → decision memo with changes, owners, and dates.
Interviews: structure without scripting the conversation
The 30-minute guide (skeleton)
- Warm-up (2–3 min): context, role, how they currently do X.
- Recent story (8–10 min): “Tell me about the last time…” (timeline: trigger → steps → obstacles → outcome).
- Switching costs (5–7 min): alternatives considered, why not switch, anxieties.
- Artifacts (3–5 min): ask for screenshots, docs, or examples.
- Debrief (3–5 min): what almost stopped you? what would 10/10 look like?
Live AI note-taker (guardrailed)
- Captures verbatim quotes with timestamps, action items, and entities from your glossary.
- Forbidden: inferring emotions, inventing numbers, or summarizing beyond quotes while the interview is running.
- Marks unclear audio and flags follow-ups for the moderator.
Consent snippet (read before recording)
“We’re recording for internal analysis. Your words may be quoted anonymously with your permission. You can stop at any time. We will not store personal identifiers in our research repository.”
Summaries: compress to a rubric, not a vibe
Use these four artifacts after each interview
- JTBD sheet
- Job, desired outcome, constraints, triggering context.
- Top pains/gains (ranked) + 3 quotes with timestamps.
- Objections & anxieties
- Cost, trust, effort, switching, risk; each with evidence.
- Opportunity notes
- Unmet needs mapped to product areas; confidence (High/Med/Low) based on source coverage.
- Signals & edges
- Surprises, contradictions, or outliers that deserve a deeper look.
Summary system prompt (essentials)
- Use only the transcript + glossary.
- For every non-obvious statement include a quote with timestamp.
- No invented numbers; mark gaps explicitly.
- Output sections: JTBD • Triggers • Obstacles • Alternatives • Objections • Opportunities.
Insight mining: from quotes to decisions
Build a living codebook
Start with 15–30 codes (e.g., “setup friction,” “pricing fairness,” “integration blockers,” “proof needed”). Let AI pre-tag each quote; researcher confirms or edits.
Affinity mapping (AI-assisted)
- Cluster codes → candidate themes.
- Ask AI for proposed theme names + definitions, then a human merges/splits.
- For each theme produce: definition, strength (coverage across interviews), representative quotes, counter-evidence, and recommended action.
Insight Cards (the deliverable)
- Claim: one sentence, falsifiable.
- Evidence: 3–5 quotes (links/timestamps).
- Confidence: High/Med/Low + why (sample size, contradictions).
- Impact: $/risk or scope estimate.
- Decision: what we’ll change, owner, date.
Governance & ethics (non-negotiables)
- Consent: written or recorded; easy opt-out.
- PII handling: redact names/emails/phones before indexing; store consent separately from transcripts.
- Data minimization: keep research repository text + snippets; keep raw video in limited-access cold storage.
- Bias checks: diversity in recruiting; track who you talked to vs target market; avoid leading questions.
- Attribution: every insight links to its quotes; every quote links to its interview.
Quality bar: how to know your research is “good”
- Grounding: % of claims backed by quotes (target ≥95%).
- Coverage: number of interviews per segment until signal saturation.
- IRR (inter-rater reliability): agreement rate between human and AI coding after review (target ≥0.7).
- Time to insight: interview → Insight Card published (target ≤48–72h).
- Decision follow-through: % of Insight Cards that lead to a shipped change.
30/60/90 rollout
Days 1–30 — Foundation
- Draft interview guide and consent; define glossary and codebook v1.
- Set up secure recording → transcription → redaction pipeline.
- Configure summary rubric + templates and the Insight Card format.
Days 31–60 — Pilot
- Run 10–15 interviews across 2 segments.
- Build the quote bank and theme map; publish 6–10 Insight Cards.
- Measure grounding, IRR, and time to insight; tune rubrics and codes.
Days 61–90 — Scale
- Add support-ticket and NPS text to the repository; re-use the same codebook.
- Automate weekly “New Signals” digest to product/marketing.
- Create a research backlog with open questions, owners, and due dates.
Tool-agnostic stack (simple & safe)
- Capture: calendar + secure recorder with consent tickbox.
- Transcribe: on private endpoints; diarize; redact PII.
- Store: transcripts + quotes in a searchable repo with RBAC.
- Summarize: rubric-based templates that require quotes and timestamps.
- Mine: pre-coding + clustering; human review; export Insight Cards to your wiki.
- Govern: logs, versioned rubrics/codebook, and a monthly audit.
Quick checklists
Before interviews
- Research question and segments defined
- Recruit list and screener approved
- Consent script/templates ready
- Glossary loaded (product terms, competitors)
After each interview
- Transcript cleaned + PII redacted
- JTBD, Objections, Opportunities summaries created
- 3–5 quotes added to quote bank with timestamps
Before reporting
- Themes reviewed by a second researcher
- Insight Cards include evidence and confidence
- Decisions, owners, and dates assigned
Conclusion
AI can’t decide what matters, but it can make the path from raw story to defensible insight dramatically shorter. Treat interviews as human craft, summaries as rubric-driven outputs, and insight mining as an evidence pipeline—then link every decision back to the words your customers actually said.


Add comment