
A private marketing copilot is an internal AI assistant that can read your brand canon, playbooks, KPI dictionary, and performance history—and answer questions or draft work under your security and compliance rules. Unlike public chatbots, it runs inside your perimeter (VPC or on-prem), accesses approved datasets only, and leaves an audit trail. The payoff: faster briefs and reports, fewer QA loops, and a shared understanding of “how we do things.”
What makes it “private”
- Deployment: hosted in your VPC or on-prem with private inference endpoints, disabled vendor retention/training.
- Access: SSO, RBAC/ABAC, and read-only connectors to analytics, MRM, CRM, and your knowledge base.
- Governance: prompts encode policy (“no invented numbers,” “cite source”), outputs are scanned for sensitive strings, and every action is logged.
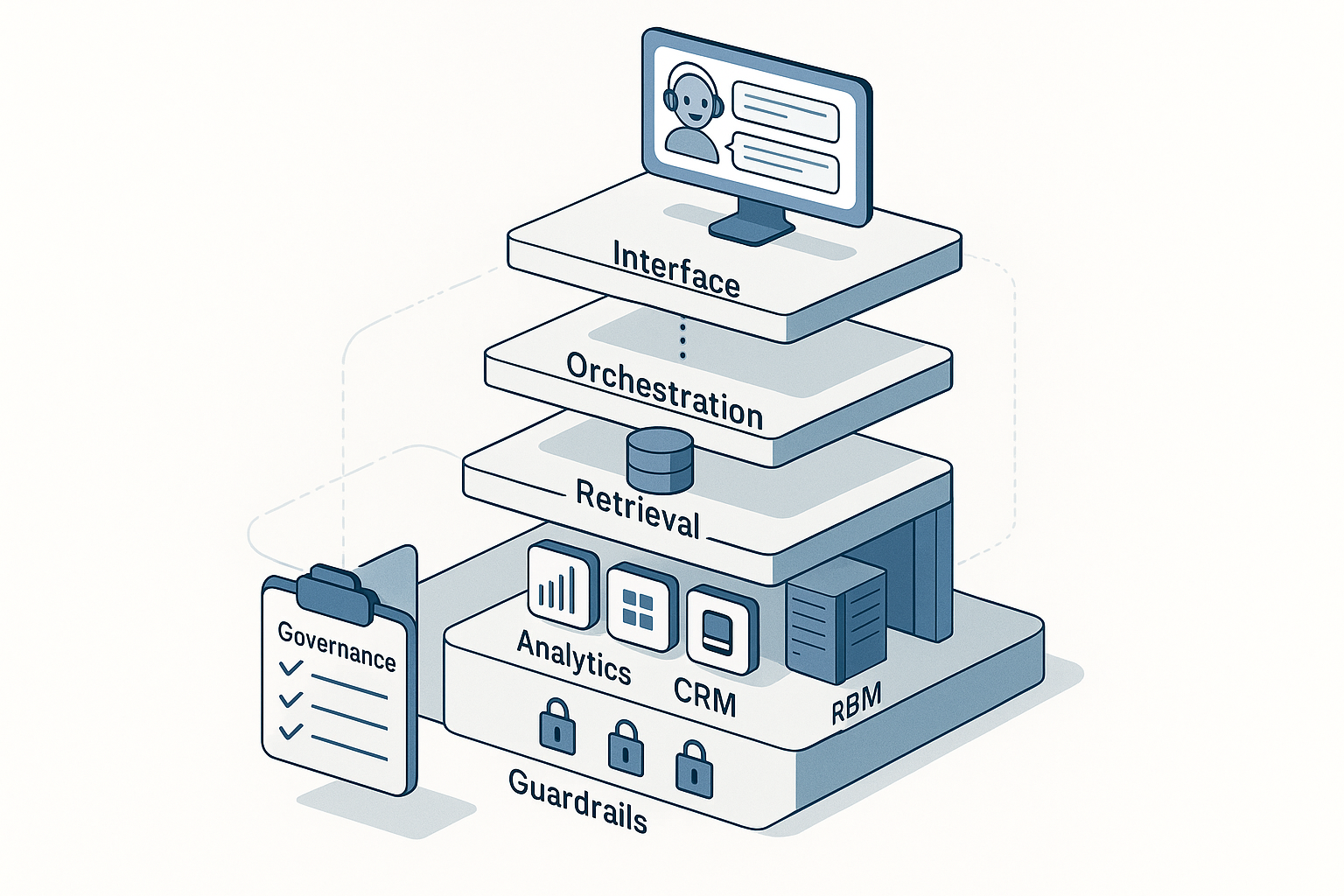
The reference architecture (at a glance)
Interface: Web app and Slack/Teams app with chat + action sidebar.
Orchestrator: Routes requests to tools (retrieve, analyze, draft, QA).
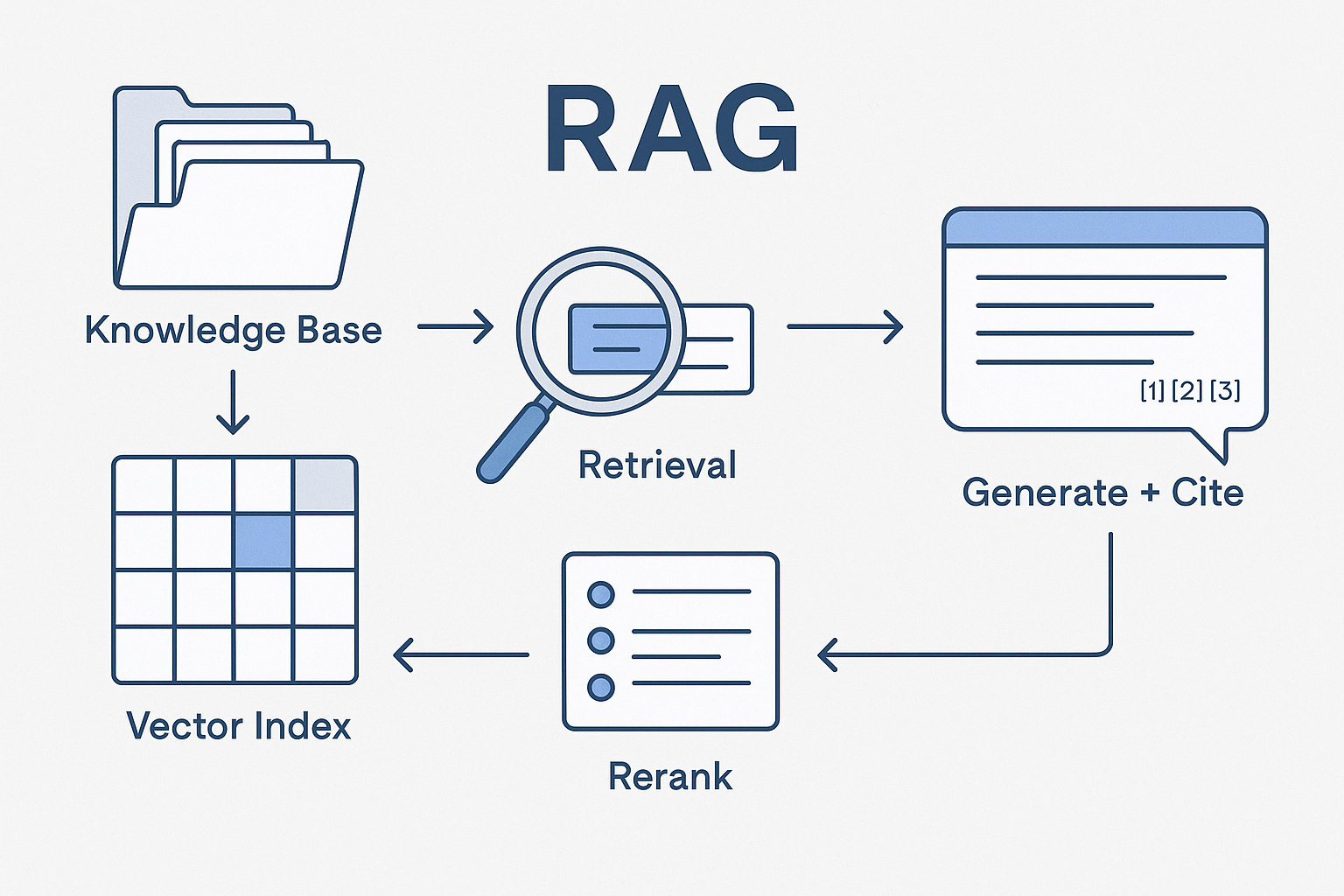
Retrieval: Vector database over curated corpora (brand, ops, performance, legal).
Reasoning: Foundation model via private endpoint; lightweight models for classification, extraction, and safety.
Tools: Read-only access to the analytics warehouse, CDP, CMS/MRM, knowledge drive, ticketing.
Observability: Traces, token/cost metrics, evaluations, red-team results.
Treat prompts, policies, datasets, and evaluations as versioned code. Release notes aren’t just for software anymore.
The data layer: include first, defer later
Include first (“low-risk, high-leverage”)
- Brand canon: voice & tone, message architecture, positioning, approved claims, visual rules.
- Performance canon: KPI dictionary, naming conventions, dashboards explanations, post-mortems.
- Ops canon: SOPs for briefs, UTM/GA4 rules, release checklists, accessibility/legal checklists.
- Public or publishable content: press pages, case studies, product sheets.
Gate or defer
- Raw PII/PHI/PCI, support transcripts, unredacted CRM notes, sensitive legal/finance docs.
Preparation steps
- Normalize to HTML/markdown/plain text; remove boilerplate.
- Chunk semantically (200–800 tokens) and tag with metadata: owner, version, sensitivity, locale, product, funnel stage.
- Build catalogs (e.g., “Brand Canon,” “Performance Canon,” “Legal Canon”) and force retrieval to respect policies via metadata filters.
- Add a “source card” to each chunk (title, link, last review date) for automatic citations.
Security & governance: non-negotiables
- Isolation: private endpoints; no model training on your prompts or outputs; KMS-backed secrets.
- Least privilege: read-only connectors; dataset allowlists; output size limits.
- Prompt guardrails: system prompt with explicit rules (no PII, cite metrics source, no legal advice without reviewer route).
- Output scanning: NER/regex for PII, banned terms, and compliance phrases.
- Audit: store telemetry (tools used, corpora touched, latency, user ID), not full chats unless required by policy.
- Compliance mapping: maintain a control matrix aligned to SOC 2 / ISO 27001; review quarterly.
High-leverage use cases you can ship
- Brief Builder: Generate campaign briefs from brand canon + past winners. Output includes message map, audience JTBD, creative checklist, and UTMs that match your rules.
- Content QA: Paste copy → get voice alignment, claim validation with citations, link/UTM checks, accessibility and legal footers—returned as a structured diff.
- Reporting Copilot: “Explain last week’s paid search.” Pulls KPI definitions, outlines drivers and anomalies, drafts a stakeholder note with chart callouts.
- Competitor Snapshot: Crawl public pages, compare to your positioning, produce deltas and counter-moves with risk flags (claims, pricing).
- SOP Q&A: Natural-language answers with snippets from the canonical SOP and examples for UTM names, file taxonomy, or review steps.
- Experiment Prioritizer: Score backlog by impact/effort/risk; returns ranked list with rationale and Definition of Done.
Phase 1 rule: read-only everywhere. No writes to prod systems until governance is proven.
90-day rollout (realistic)
Days 1–14 – Foundation
- Choose 2–3 use cases (Brief, QA, Reporting).
- Stand up VPC, SSO, logging, and a small admin panel.
- Curate corpora (Brand, Performance, Legal) and index with metadata.
- Draft system prompts and red-team tests (hallucination, policy, PII).
Days 15–45 – Pilot
- Ship to 8–12 power users; collect failure cases; improve retrieval filters.
- Add analytics connector (read-only) and a “cite before analyze” rule.
- Create an evaluation harness: golden prompts + rubric (factuality, policy, tone, usefulness).
Days 46–90 – Scale
- Expand RBAC, add role-specific prompts, and token budgets.
- Introduce small-model routing for classify/extract tasks; add caching.
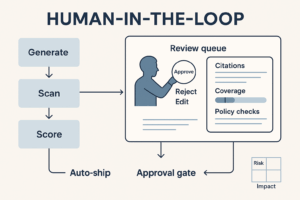
- Publish SOPs for prompt hygiene, HIL (human-in-the-loop) review, incident response.
Measuring impact (to win finance)
- Cycle time: median minutes to first draft brief/report.
- Quality: edit count per asset; % assets passing QA on first pass.
- Coverage: % SOPs searchable; % dashboards with pinned definitions.
- Risk: violations caught by output scanner; red-team pass rate.
- Cost: tokens per resolved task; cache hit rate; spend per active user.
Set explicit targets (e.g., 50% faster briefs, 30% fewer QA reworks, 0 critical policy violations) and report weekly during the pilot.
Risk playbook
- Hallucination → Force retrieval; reject uncited facts; show “confidence/coverage” indicators; require human sign-off for external copy.
- Data leakage → Pre-index redaction; zero write permissions; periodic access audits; “print/no-print” policy for chat logs.
- Model cost drift → Response length caps, classification/extraction with smaller models, answer compression, caching.
- Governance drift → Quarterly policy review; eval benchmarks under version control; change-log on the admin panel.
Pragmatic stack choices (vendor-agnostic)
- Hosting: VPC or on-prem inference with private endpoints.
- Retrieval: vector DB + hybrid search; metadata filters by sensitivity and department.
- Connectors: warehouse (read-only SQL), CMS/MRM (read-only), drive/KB, web crawler restricted to allowlists.
- Orchestration: router that decides retrieve/generate/QA; tool-use traces.
- Admin UX: corpus manager, RBAC, prompt/policy versioning, release notes.
Workflow examples
Brief Builder prompt (system)
- “Follow Brand Canon v3.1. Cite sources for all claims. No invented numbers. Output sections: Context → Audience (JTBD) → Message Map → Offer → Channels → Creative Checklist → UTMs (naming rules v2.4).”
Reporting Copilot flow
- User asks: “Summarize last week’s paid search.”
- Bot fetches KPI definitions (“Spend,” “CPA,” “Assisted Conv.”) and last 7 days vs previous.
- Bot returns: 5-line summary + 3 drivers + 2 anomalies + a note to stakeholders + links to dashboards, each with dictionary citations.
Content QA diff
- “Voice: 2 inconsistencies (replace buzzwords); Compliance: add disclaimer §3.2; Accessibility: add alt text; Links: 1 broken UTM; Claims: cite case study #41.”
FAQ
Isn’t this just knowledge management with a chat UI?
It’s knowledge management + policy-aware reasoning. Retrieval ensures the bot knows, policies ensure it behaves.
Can we keep PII out entirely?
Yes. Redact at ingestion, block PII chunks by metadata, and scan outputs. Start with corpora that contain zero PII.
Which model should we pick?
Start with a strong general model via private endpoint for generation and a small model for classify/extract. Optimize later with caching and routing.
What’s the fastest first win?
Content QA or Brief Builder. Both cut cycle time and encode brand rules without touching customer data.
Will teams trust it?
Trust grows when the bot shows sources, follows house style, and reduces rework. Run a 4-week pilot with measurable targets and publish weekly deltas.
Conclusion & next step
A private marketing copilot lets teams move faster without giving up control. Start narrow, ship read-only, measure visibly, and codify your brand canon as the bot’s operating system. When you’re ready, add more tools—never more risk.
CTA: Want a pilot blueprint tailored to your stack and policies? Book a $99 Marketing Systems Audit and we’ll map use cases, datasets, and a 90-day plan.


Add comment