

Thesis: “Agents” are great at doing—not deciding why. Treat agentic workflows as force-multipliers for bounded, multi-step tasks with clear success criteria. Use them to compress cycle time and cost; keep strategy, taste, and high-risk decisions in human hands with guardrails and tests.
1) What “agentic” really means (for marketers)
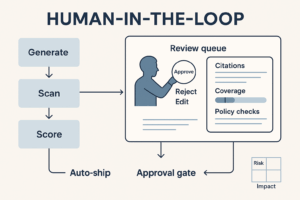
An agentic workflow is a chain of steps an AI executes autonomously: it plans subtasks, calls tools (docs, web, ads APIs, spreadsheets), checks results, and repeats until conditions are met. Think orchestrated SOPs with judgment on rails.
Design skeleton
Trigger → Retrieve context → Plan → Act (tools) → Check → Log → Hand off/Loop
Add checkpoints where a human approves, rejects, or edits before the next step.
2) Where agents shine (and measurable wins)
| Job to be done | Why agents are good | What to measure |
|---|---|---|
| Research & synthesis at scale (market, competitors, reviews) | Parallelizes search → extract → normalize → summary; tireless | Time saved per brief; researcher hours reallocated |
| Keyword/topic clustering | Deterministic embeddings + LLM labeling beat manual grouping | Coverage of search demand; cluster purity; hours saved |
| Creative variants (ads, subject lines) | Fast idea generation + rules (length, CTAs, tone) | Valid variant rate; time-to-first-draft; CTR delta in tests |
| CRM enrichment & routing | Structured extraction from emails/forms; dedupe; ICP scoring | Match rate; enrichment accuracy; lead response time |
| Campaign QA (UTMs, policy, brand rules) | Deterministic checklists + LLM linting | Defect catch rate; policy violations avoided |
| Analytics housekeeping (naming, tagging, dashboards) | Normalizes event names, flags SRM and freshness issues | Data quality score; incidents per month |
| A/B result readouts | Consistent stats templates; guardrail checks | Time to readout; false-positive prevention adherence |
Expect 20–70% cycle-time reduction on these jobs when you instrument acceptance tests and keep humans in the loop.
3) Where agents fail (or need tight fences)
- Strategy & positioning. Choosing markets, offers, or trade-offs is a leadership job.
- Thin or biased data. Agents confidently extrapolate nonsense. If ground truth is weak, stop.
- Brand nuance & taste. Voice, humor, and cohesion across channels still require human editing.
- Ambiguous success criteria. If “done” isn’t testable, agents will loop or ship junk.
- High-risk actions. Booking big budgets, pricing changes, or emailing customers unreviewed—nope.
- API flakiness/vendor lock-in. Retries and fallbacks are mandatory; don’t design brittle chains.
- Privacy/compliance gaps. Unvetted data movement, PII leakage, or consent violations kill trust.
4) The “4-P” pattern to design useful agents
- Purpose: A single business outcome (e.g., “publish a weekly competitor brief”).
- Playbook: Deterministic steps + tool calls (SOP) the agent can follow.
- Proof: Acceptance tests & eval datasets to check outputs automatically.
- Permission: Scopes, budgets, and human checkpoints.
Example – “BriefBot” (weekly competitor brief)
- Trigger: Monday 8am.
- Steps: Crawl public pages → extract deltas (pricing, features) → summarize → draft slides → flag risks.
- Proof: Must include 3+ sources; accuracy ≥95% on a small labeled set; no PII.
- Permission: Cannot email the board; posts draft to a review channel.
5) Guardrails (non-negotiables)
- Human-in-the-loop gates before any public or budgeted action.
- Eval sets & regression tests (golden examples) run on every change to prompts/tools.
- Cost and time SLOs: e.g., <$0.50/run, <5 min latency. Auto-kill runaway loops.
- Brand & compliance linting: tone/voice rules, disallowed claims, UTM policy, consent checks.
- Audit trails: log prompts, tools, outputs, approvals; immutable storage.
- Data minimization: no raw PII unless required and consented; redact at the edge.
- Sandboxed credentials with least privilege; campaign write-access behind approval.
6) Choosing the first 3 agent projects (a short rubric)
Score 1–5 on Impact, Repeatability, Testability, Risk (reverse). Start with ≥15 total.
Good starters
- Topic/keyword clustering → content calendar
- Multi-channel creative variants → QAed draft set
- UTM enforcement + naming linter
- Weekly competitor/news brief with source links
- Lead enrichment + ICP routing (metadata only)
Save for later
- Budget reallocation without experiments
- Autonomous pricing changes
- Sales outreach without human review
7) Measuring success (beyond vibes)
Operational
- Task Success Rate (TSR): % runs meeting acceptance tests
- Latency per run and cost per run
- Human edit rate & edit time (trend should fall)
Business
- Cycle time saved (hours) × blended rate
- Quality deltas (QA defect rate, naming errors)
- Experiment outcomes (CTR/CPA lift of agent-generated variants)
- Error budget (max acceptable failures before freeze)
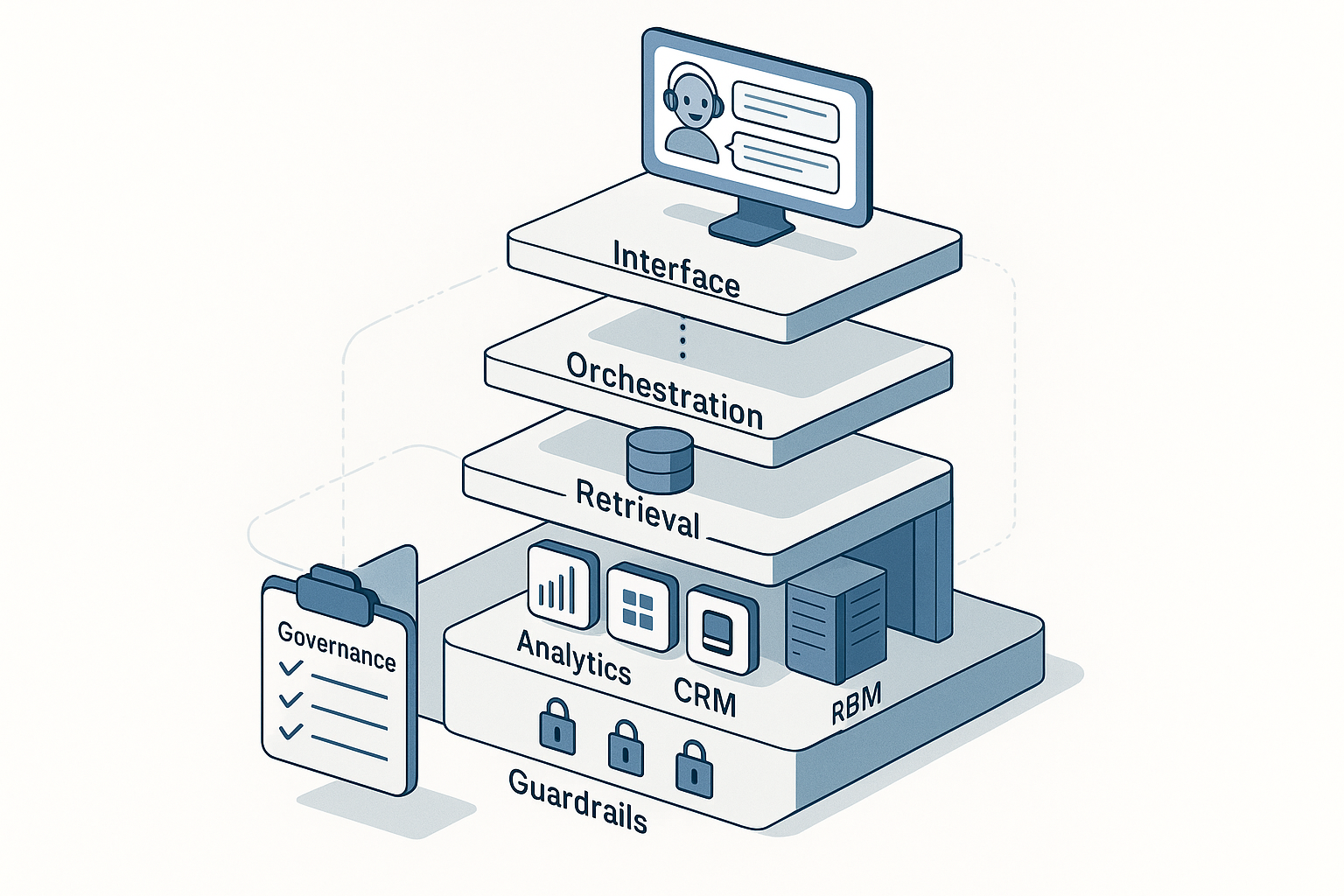
8) Architecture sketch (tool-agnostic)
- Orchestrator/Runner: runs the plan, handles retries (e.g., Airflow/Temporal/n8n/Make + an agent layer).
- Models: one general LLM + smaller specialized ones; use cheap models for draft, better ones for checks.
- Tools: web/search, Sheets/Docs, CRM/ads APIs, vector store for brand voice & product facts.
- Policies: prompt library with brand rules; red-team prompts; secrets manager.
- Storage: results + logs + evals; version prompts like code.
9) Case snapshots (illustrative)
- Keyword clustering: Agent clustered 12k queries into 380 topics in 11 minutes; strategist reviewed top 40; brief time –64%, organic sessions +8% QoQ.
- Creative variants: Weekly 25-variant set auto-generated to spec; human picked 6; A/Bs showed +7–12% CTR on two accounts; cost/run ≈ $0.38.
- Lead routing: Parsed inbound emails, extracted fields, scored ICP, assigned owner; first-response time –42%, MQL→SQL +5 pp with zero PII stored in prompts.
10) 30-60-90 day rollout
Days 1–30 — Pick & scaffold
- Select 3 low-risk workflows with clear SOPs and metrics.
- Write acceptance tests & redlines (brand, legal).
- Wire orchestrator + logs + cost guardrails; create review channel.
Days 31–60 — Pilot & prove
- Run 50–100 cycles per workflow.
- Track TSR, edit rate, time, cost; hold an A/B for one creative use case.
- Document failure modes; tighten prompts, add checks.
Days 61–90 — Scale & govern
- Add 2 more workflows or expand to more markets.
- Bake agents into weekly cadences (briefs Monday, QA daily).
- Publish Agent Runbook (owners, SLOs, rollback) and quarterly audit schedule.
11) Failure modes & fixes (cheat sheet)
- Hallucinated facts → mandate citations; reject uncited claims.
- Tool flakiness → exponential backoff; cached reads; graceful degradation.
- Brand drift → retrieval-augmented prompts with brand bible; enforce style checks.
- Runaway costs → token budgets; step limits; “cheap-draft, strong-judge” pattern.
- Approval fatigue → batch reviews; confidence thresholds to auto-approve low-risk items.
- Stale prompts → regression tests + change log; freeze before big launches.
12) What to automate next (once the basics work)
- Agent-assisted experimentation: auto-generate hypotheses from analytics; draft pre-reg; create SRM/guardrail monitors (still human-approved).
- Agent-assisted MMM-lite: prep weekly dataset, refresh curves, generate “+10k scenario” page (no autonomous reallocation).
- Customer insight miner: cluster NPS/comments into themes; surface verbatims for product & CX.
Bottom line: Use agents to buy speed and consistency on well-scoped jobs. Keep humans on strategy, taste, and anything that spends money or touches customers. That split is how agentic workflows actually move revenue—without burning trust.

Add comment