
Most teams treat creative testing like a buffet: more options must mean more learning. In practice, the opposite happens—budgets fragment, signals get noisy, and teams crown random winners. For SpectrumMediaLabs, the goal isn’t to test everything; it’s to design tests that teach. This playbook shows how to structure creative experiments that extract maximum learning from minimal variants, with clear decision rules, small sample sizes, and repeatable documentation.
The mindset: decisions > winners
A test is successful if it changes a decision you would have made otherwise. Start with three statements:
- Decision: “If variant X beats baseline on our primary metric by ≥ MDE, we’ll roll it across campaigns A/B/C.”
- Hypothesis: “Framing the headline as a result (vs. a feature) increases first-frame hold by 10% among problem-aware viewers.”
- Stop rules: “Run until we hit N impressions per arm or 14 days, whichever comes first, unless an interim harm threshold triggers a stop.”
If you can’t write those in one minute, you’re not ready to launch variants.
A simple model: Concept → Message → Execution
Don’t mix levels. You’ll learn faster by isolating layers:
- Concept (spine): the idea that holds the story together (e.g., Proof-led vs. Myth-bust).
- Message: headline/CTA, benefit framing, objection handling.
- Execution: hook visuals, pacing, typography, color, thumbnail, soundtrack.
Rule: One test ≠ one layer. Test within a single layer first; only explore interactions after you have a strong base.
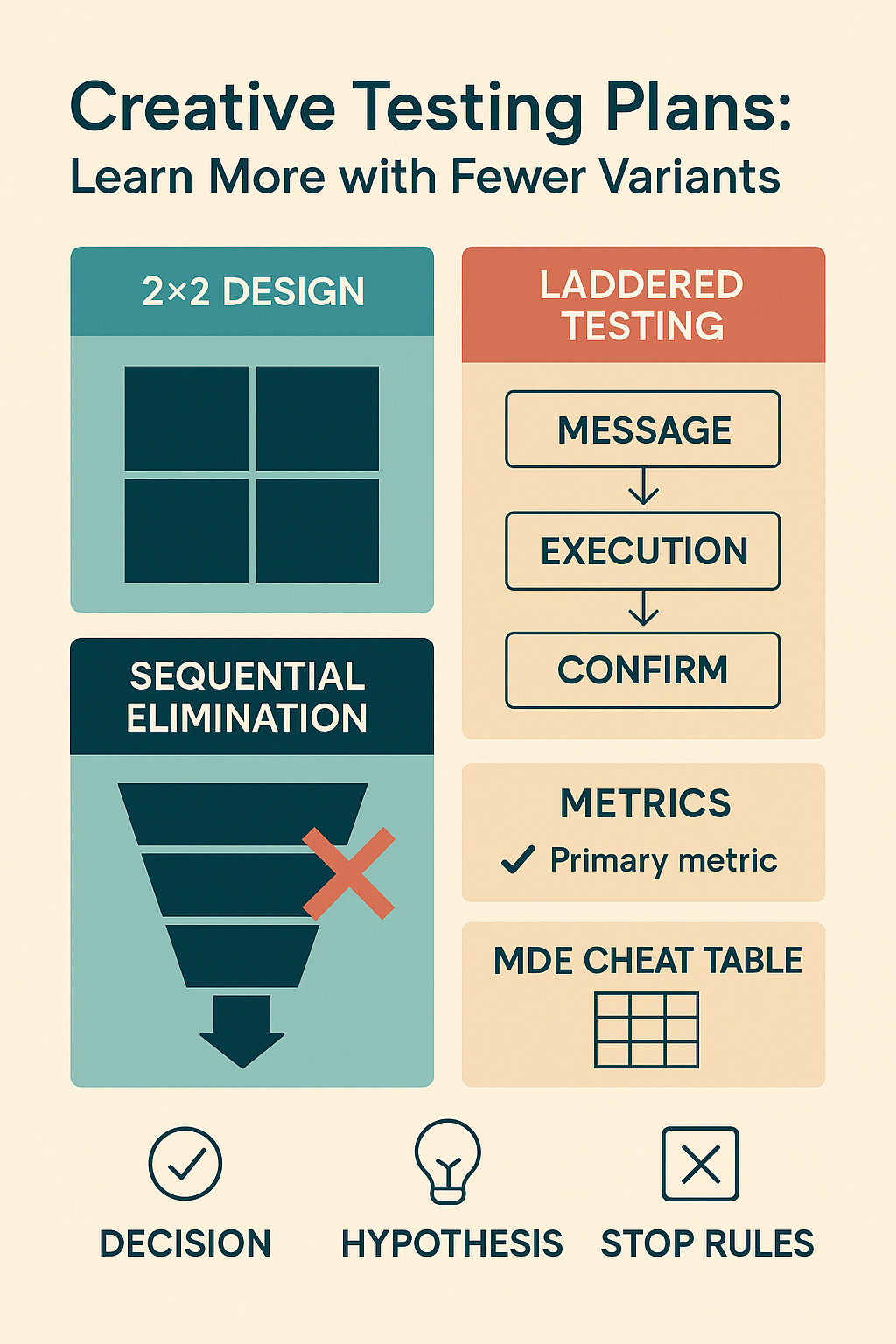
Design patterns that reduce variants (but increase learning)
1) Screening with a small fractional factorial
When you must check multiple messages, use a 2×2 (or 2⁴ fractional) instead of eight unrelated ads.
- Example (Messages):
- Factor A: “Result-first” vs “Feature-first”
- Factor B: “Proof (logo)” vs “Proof (stat)”
- You ship 4 variants, not 8, and can estimate main effects + the A×B interaction.
When to use: early exploration, limited budget, you need directional answers.
2) The 3–5 Prototype Rule (per concept)
At the execution layer, cap to 3–5 prototypes:
- Hook frame (1 visual difference)
- On-screen text (≤7 words, two wordings)
- CTA (one distinct placement)
You’re testing decisive elements, not micro-ornaments.
3) Sequential elimination (fast-fail)
Instead of equal spend to the end, prune losers early with conservative rules:
- After 25–30% of target impressions, pause any arm that is >1.5× worse on the primary metric with a minimum exposure floor (to avoid early randomness).
- Reallocate budget to survivors; confirm with fixed-horizon endpoints.
This saves budget without bandit complexity.
4) Laddered testing
Move from message → execution → scale:
- Message screen (2–4 variants) → pick 1–2.
- Execution screen inside the winning message (3–5 prototypes) → pick 1–2.
- Confirmation (winner vs baseline) with clean power.
You learn why something works, not just which ad won.
Metrics that actually teach
Pick one primary metric aligned to the decision horizon:
- First-frame hold (3s / 2s view): hook strength for short-form.
- ThruPlay / 50% view: story pacing quality.
- Primary CTR or Profile clicks: message-market fit.
- Cost per qualified action (down-funnel proxy): when testing for performance, not creative craft.
Track secondary diagnostics (save/share, comments, profile visits) but don’t let them override the primary.
Sample size & MDE, minus the math headache
You need just enough impressions to detect a Minimum Detectable Effect (MDE) that matters to your business.
- Choose baseline rate (e.g., CTR 1.2% or 3s-hold 60%).
- Choose MDE (e.g., +15% relative).
- Set α=0.05 and power 80%.
- Use a simple calculator once; then keep a cheat table for your common metrics.
Rules of thumb (rough, per arm):
- For a baseline CTR ~1% and MDE +20% → ~80–120k impressions/arm.
- For 3s-hold from 60% with MDE +8% → ~25–40k impressions/arm.
If you can’t afford the sample for your MDE, test bigger differences (earlier in ideation) or reduce variants.
Preventing false learning (the usual traps)
- Novelties fade. Re-run the winner after two weeks; if it collapses, you crowned novelty.
- Frequency bias. Cap frequency in tests; creative fatigue is not a “loser.”
- Audience drift. Fix audience/placement where possible; document any platform optimization that might skew arms.
- Peeking. If you must peek, use a single interim check with a harm threshold; don’t chase mid-test flips.
- Winner’s curse. Confirm the winner in a short hold-out confirmation (winner vs baseline only).
Operational blueprint
Test brief (one page)
- Decision, Hypothesis, Stop rules (as above)
- Layer: concept | message | execution
- Primary metric: ______
- Baseline & MDE: ______
- Audience/placements: (fixed) ______
- Budget & sample: ______
- Risk control: frequency cap, geography, brand safety, rights
Naming convention
SML-2025Q4-TEST17_MSG_A1B0_primaryCTR_MDE15_confirm
Creative taxonomy (keep it tight)
- Hook visual: face | product | UI | object motion
- Headline intent: result | feature | myth-bust | challenge
- Proof: logo | stat | artifact | none
- CTA: save | comment | click | follow
If a label isn’t in the taxonomy, don’t test it yet.
Design matrix templates
A) 2×2 message screen (CSV)
test_id,variant,headline,proof,primary_metric
TEST17,A,result,logo,CTR
TEST17,B,result,stat,CTR
TEST17,C,feature,logo,CTR
TEST17,D,feature,stat,CTR
B) Execution screen (hook/CTA within winning message)
test_id,variant,hook_frame,cta_position,primary_metric
TEST18,A,face_close, end_card,3s_hold
TEST18,B,ui_zoom, end_card,3s_hold
TEST18,C,object_motion, mid_card,3s_hold
TEST18,D,face_close, mid_card,3s_hold
C) Confirmation
test_id,variant,role
TEST19,WINNER,challenger
TEST19,BASELINE,control
Platform specifics (keep the plan platform-agnostic)
- TikTok/Reels/Shorts: optimize for first 2–3s hold and replays/saves; hook and on-screen text are the levers.
- Meta (Feed/Stories): protect audience parity; Meta will auto-allocate spend—use separate ad sets per variant when you need equal delivery.
- YouTube: thumbnail + title are often bigger levers than the first 5s; test them before editing micro-beats in the video.
Documentation that compounds learning
- Store creative + metrics + decision in a searchable log (Notion/Airtable):
concept_id,message_labels,hook_type,cta,asset_link,audience,metric,result,decision,notes.
- Add screenshots or first frames; no one revisits a folder of filenames.
- Publish a quarterly playbook: “What worked for problem-aware PMs in Trust topic,” with 3–5 reusable spines.
Example: Learn more with just four variants
Objective: Lift CTR for a feature announcement by ≥15% (MDE) in the Consideration cohort.
Layer: Message.
Design: 2×2 (Result vs Feature) × (Proof logo vs Proof stat).
Primary metric: Link CTR.
Sample: 100k impressions/arm (based on baseline CTR 1.0%).
Stop rules: pause any arm <0.6× control after 30k impressions.
Decision: If any arm clears +15%, roll message across IG Feed + Stories; next step—execution screen with hook frames.
Outcome: You learn which proof type carries the message and whether result-first beats feature-first, with four ads—not twelve.
QA & ethics (non-negotiables)
- Rights & credits attached; no “editorial only” stock in ads.
- Accessibility: captions, readable text (contrast ≥4.5:1), no flashing >3/s.
- Claims: numbers require a citation; keep in the playbook.
30/60/90 roll-out
Days 1–30 (Foundations)
- Publish the testing brief template, taxonomy, and naming scheme.
- Build a simple MDE table for your common baselines (CTR, hold rates).
- Run one message screen with a 2×2 design.
Days 31–60 (Scale & Discipline)
- Add sequential elimination rules; set up dashboards for primary metric vs spend.
- Launch execution screens within winning messages; keep to 3–5 prototypes.
- Start the learning log; share a biweekly summary to stakeholders.
Days 61–90 (Confirmation & Playbooks)
- Confirm winners in head-to-head tests; promote to the base library.
- Publish the Quarterly Creative Playbook (top spines, hook frames, CTAs by audience).
- Reduce default variant count in briefs; require a reason to exceed 5.
Ship-ready checklists
Test readiness (stop if any box is empty)
- Decision + MDE defined
- Single layer per test (concept/message/execution)
- ≤5 variants, labeled by taxonomy
- Sample budget matches MDE table
- Audience/placements fixed; frequency capped
- Stop rules + ethics checks set
Post-test
- Winner confirmed (or not) vs baseline
- Learning logged with assets
- Next test proposed (laddered plan)
Bottom line
“Fewer variants” isn’t about doing less—it’s about designing better. By isolating layers, using small factorials, pruning losers early, and confirming only what matters, SpectrumMediaLabs can learn faster on the same spend. The output is not just a new ad; it’s a reusable creative playbook that makes the next dozen ads smarter.
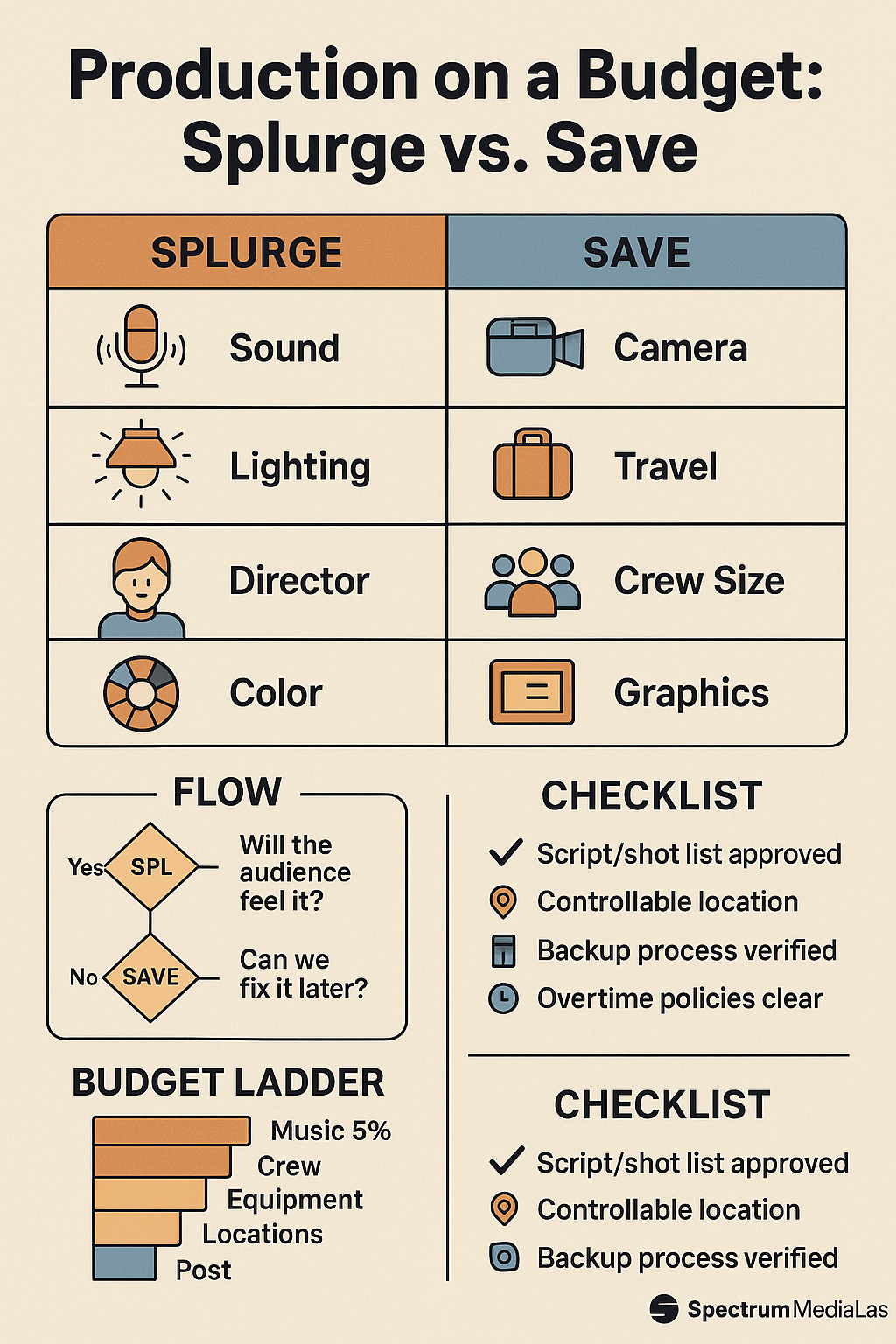




Add comment