
Most marketing teams struggle to test enough creative ideas before a launch. Budgets are limited, audiences are fragmented, and every platform favors speed. Synthetic data—artificially generated text, images, audio, or structured events—can help you explore more variants, isolate variables, and forecast performance before you spend on media. Done well, it shortens creative cycles and reduces waste. Done poorly, it amplifies bias, misleads stakeholders, and creates legal risk.
This guide shows how to use synthetic data responsibly in a marketing context: where it helps, where it doesn’t, and the guardrails you need.
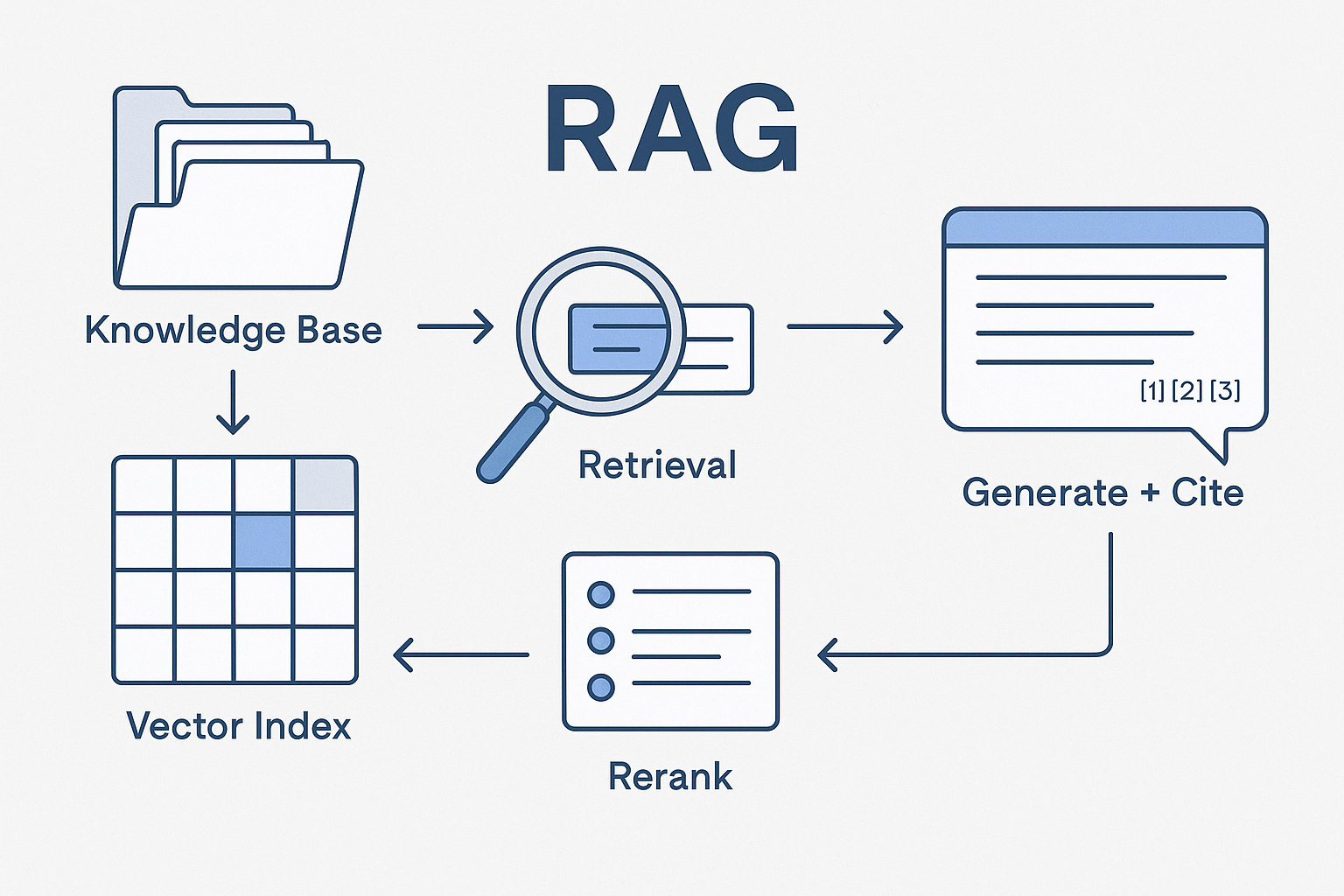
What “synthetic data” means for marketers
- Programmatic text & images: headline variations, product shots, lifestyle scenes, scripts, thumbnails.
- Behavioral simulations: predicted scroll depth, dwell time, or click propensity generated from models trained on historical, consented data.
- Scenario datasets: synthetic “exposures” (impressions with attributes) used to pre-rank creative concepts.
The point isn’t to replace real users. It’s to de-risk which ideas deserve real budget by filtering and shaping your test plan.
When synthetic data is useful (and when it isn’t)
Use it when you need to:
- Expand the option space quickly (e.g., 200 headline/visual/CTA combinations → shortlist of 12 to live test).
- Isolate variables (color vs CTA vs layout) without noisy field conditions.
- Protect privacy by avoiding raw user data during creative iteration.
- Cover edge cases (rare locales, screen sizes, accessibility checks) you rarely hit in small A/B tests.
- Backtest hypotheses against historical, consented data without re-contacting users.
Avoid or limit it when:
- You lack any ground truth to anchor simulations (no prior campaign data and no clear objective metric).
- Decisions hinge on taste and brand feeling that your brand team must judge live.
- The legal, compliance, or platform policies are unclear (e.g., endorsements, likeness, political or sensitive categories).
Responsible principles (memorize these)
- Purpose limitation
Be explicit: “We generate variants to prioritize concepts for live testing, not to claim real-world lift.” - Data hygiene
Train or calibrate only on consented, policy-compliant data. Strip identifiers; aggregate where possible. - Model isolation
Use private endpoints or models with no-training on your prompts/assets. Keep logs and artifacts in your VPC. - Bias and harm checks
Red-team for stereotyping, exclusionary language, and fairness across segments. Document results and fixes. - Provenance & auditability
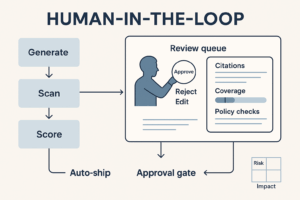
Track which model, prompt, seed, and assets produced each synthetic output. Version everything. - Human in the loop
Brand/Legal/Accessibility sign-off before anything goes public. Synthetic ranking is advisory, not authoritative.
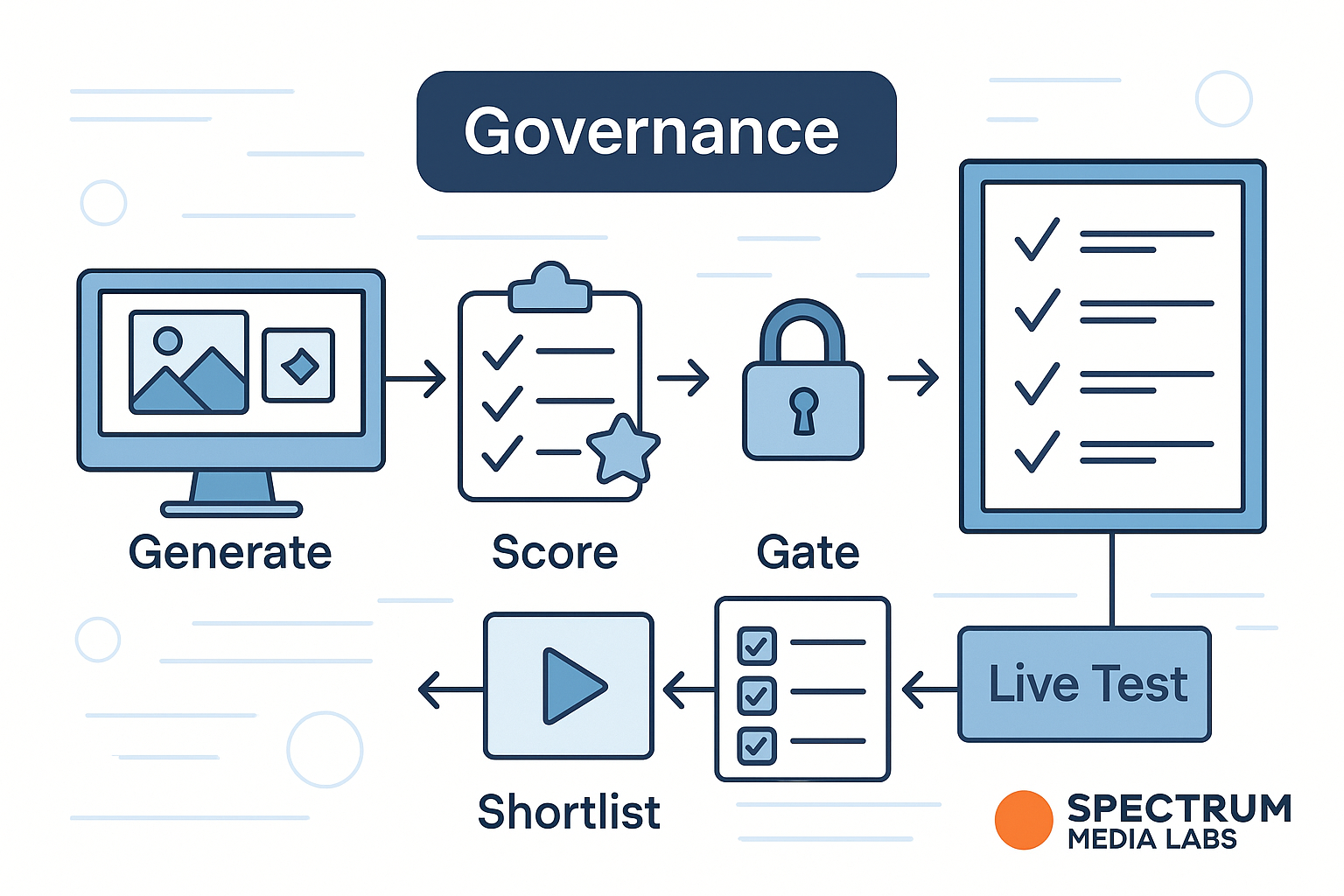
A practical workflow (6 steps)
1) Frame the decision
- Problem: “Which three concepts deserve live budget for Product X launch in DE/FR?”
- Success metric: short-term proxy (predicted click propensity + readability + brand safety score).
- Constraints: house style, legal lines, accessibility minimums.
2) Generate the matrix
- Define dimensions: Headline × Visual motif × CTA × Colorway × Format.
- Use Latin square or fractional factorial design to reduce combinations without bias.
3) Build or choose the proxy models
- Readability (text complexity), accessibility (contrast, alt-text presence), brand voice similarity, compliance flaggers.
- Optional: a click-propensity model trained on your historical, consented data (not third-party black boxes).
4) Score + rerank + shortlist
- Score each variant; apply hard gates (brand safety, accessibility).
- Rerank on the weighted proxy score; pick the top 10–15 for human review.
5) Human review & calibration
- Brand and Legal review the shortlist; remove anything off-tone or risky.
- Calibrate scores based on reviewer decisions (e.g., down-weight over-clever headlines).
6) Live test (small, real audience)
- Launch the final 6–12 variants with budget caps and pre-registered analysis (what constitutes a winner).
- Compare live performance vs synthetic ranks → compute rank correlation and update your models.
What to generate (and what to never generate)
Good candidates
- Copy: 50–200 headlines and post texts following house style and approved claims.
- Visuals: product-in-context shots, backgrounds, colorways, layout sketches.
- Thumbnails & hooks: first frames for video; safe “pattern interrupts.”
- Micro-content: alt text, captions, on-image copy for accessibility and clarity.
Hard no / heavy caution
- Real people’s likeness without explicit, written permission.
- Competitor marks or trade dress.
- Fabricated testimonials or implied endorsements.
- Sensitive attributes (health, beliefs) in targeting or messaging without strict legal review.
Validation: making sure synthetic rankings aren’t fantasy
- Backtesting: Run the pipeline against last quarter’s consented campaigns. Measure how well synthetic ranking predicts actual CTR/CVR order.
- Negative controls: Include a purposely bad variant (e.g., low contrast, jargon-heavy copy). Your pipeline should down-rank it.
- Holdouts: Keep a few top human-picked ideas that the model disliked; compare in live tests.
- Drift checks: Re-evaluate monthly; if platform formats change, retrain or recalibrate.
Measuring value (the finance-proof way)
- Cycle time: time from brief to shortlisted variants (target −40–60%).
- Waste avoided: number of variants filtered out before paid traffic.
- QA defects: accessibility/compliance issues caught pre-launch.
- Predictiveness: rank correlation (Spearman) between synthetic ranks and live outcomes.
- Cost per resolved decision: modeling + generation spend vs lift in test velocity.
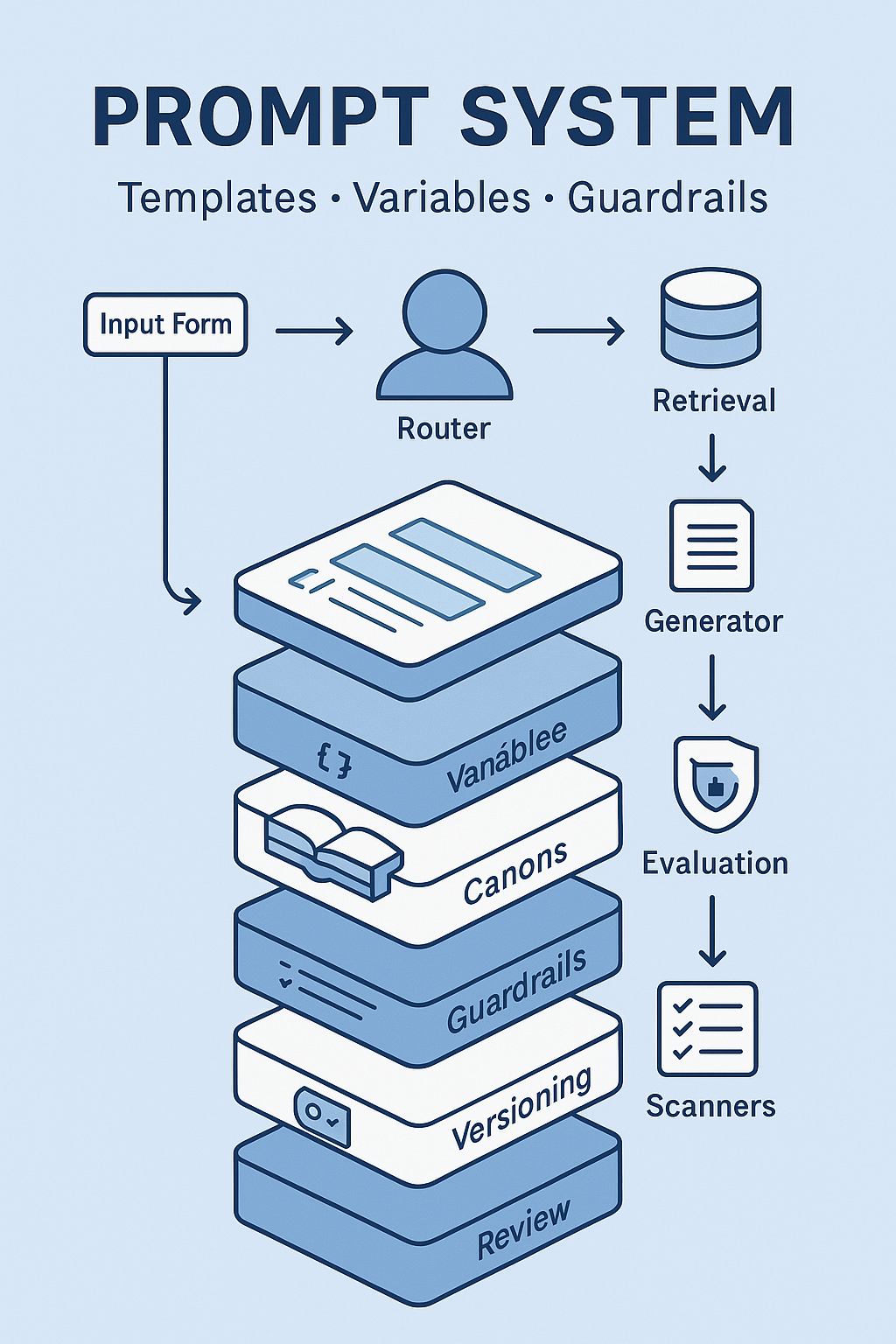
Governance & policy you’ll actually use
- System prompt policy: no invented product claims; cite Canon references; require alt-text; ban embargoed terms.
- Asset gate: only approved logos, brand colors, and fonts; store in a read-only “Brand Canon.”
- Licensing & IP: confirm commercial rights for generated images; save license terms with each artifact.
- Disclosure: if synthetic imagery is used in organic content, follow your brand’s transparency policy.
- Incident playbook: criteria for pulling a synthetic variant, who signs off, and how to notify stakeholders.
Example: a safe synthetic pre-test (fictional, process-only)
- Team defines three creative concepts for a note-taking app: Focus, Speed, Clarity.
- Pipeline generates 90 copy/visual combos; applies gates for banned phrases, contrast ratios, and claim wording.
- Reranker promotes variants with plain-language benefits and strong focal points; demotes dense text on mobile.
- Brand/Legal pick 12 for live; two “human favorites” that scored lower are kept as controls.
- Live test shows moderate alignment with synthetic ranks; model updated to weight “human-like” phrasing more heavily.
No fabricated performance claims—only process and alignment.
Implementation blueprint (30/60/90)
Days 1–30 — Foundation
- Document objectives, guardrails, and the decision cadence.
- Stand up private inference; create the Brand Canon (approved words, claims, disclaimers).
- Build the generation grid; implement readability, accessibility, brand-voice, and compliance scorers.
Days 31–60 — Pilot
- Run two pipelines (e.g., paid social + YouTube thumbnails).
- Backtest on prior campaigns; compute rank correlations.
- Start a governance register (bias tests, incidents, model versions).
Days 61–90 — Scale
- Add a consented click-propensity model trained on your data.
- Automate artifact provenance (prompt, seed, model hash, rights).
- Publish an SOP: “How to request synthetic pre-tests,” including SLAs and review steps.
Risk → mitigation quick table
| Risk | Mitigation |
|---|---|
| Biased or stereotyping images | Red-team prompts; blocked terms; reviewer checklist for representation and inclusion |
| Non-compliant claims | Canon-based claim library; automatic claim matcher; Legal review gate |
| Overfitting to proxies | Keep live tests small but frequent; update weights using rank correlation, not absolute lift |
| IP/licensing exposure | Use owned assets or models with commercial rights; store license with artifact |
| Data leakage | Private endpoints; no-training clauses; purge/temp storage; role-based access |
| Stakeholder overconfidence | “Advisory, not decisive” labels; confidence bands; publish calibration reports |
Quick checklists
Creative lead (before generation)
- Campaign objective, audience, channels
- Approved claims & disclaimers
- Must-use assets (logo, colors, fonts)
- Variables to explore (layout, CTA, hook)
Analyst (after scoring)
- Confirm gates fired (accessibility, compliance)
- Review top 10 for diversity of ideas
- Prepare backtest vs historical campaigns
Brand/Legal (final gate)
- Off-brand phrases, cultural context, inclusivity
- Claim accuracy and disclosure lines
- Final shortlist for live A/B

Add comment