
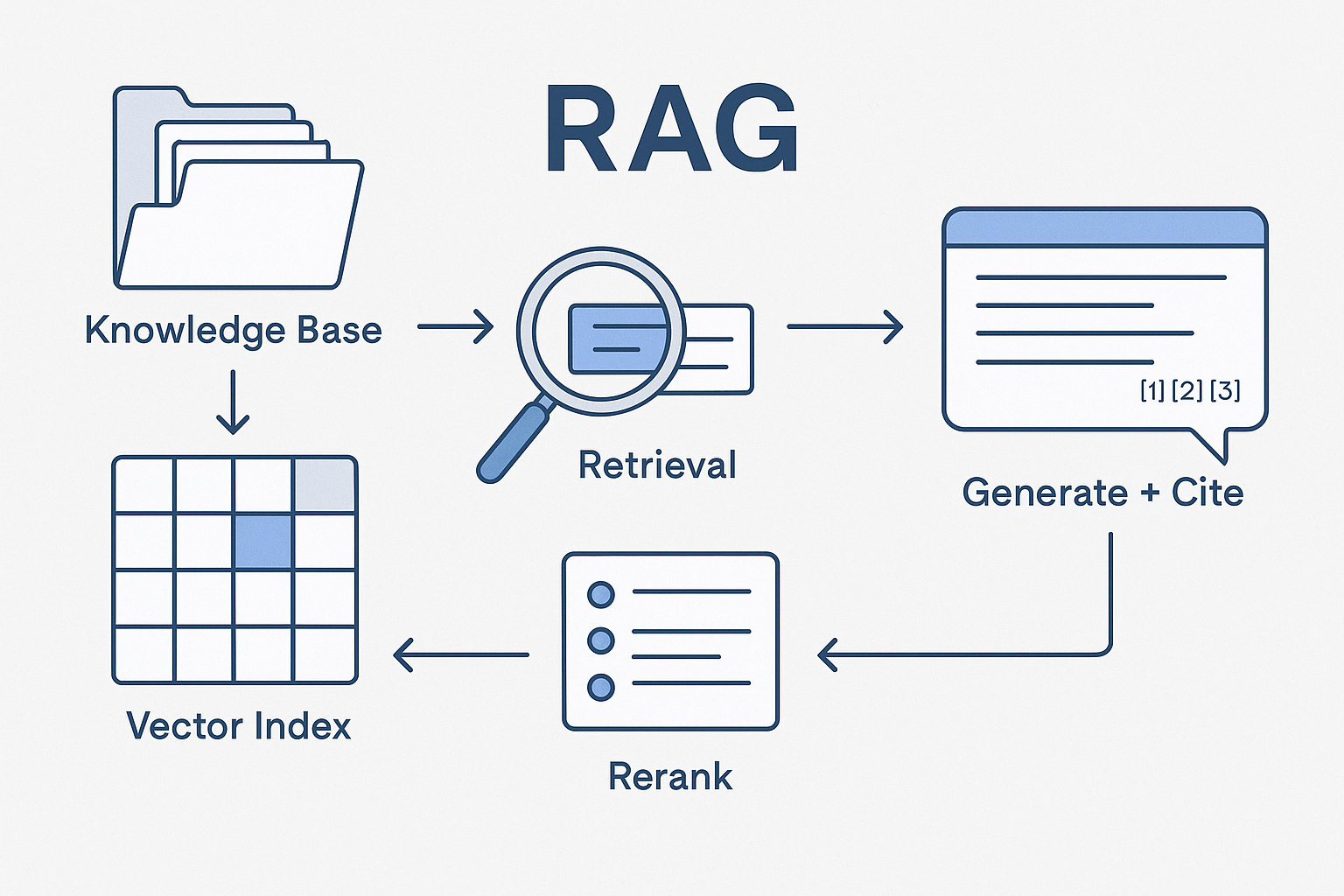
Most teams already have the raw materials for great answers—brand books, style guides, KPI dictionaries, case studies, naming conventions, legal boilerplates—scattered across drives, wikis, and dashboards. Retrieval-Augmented Generation (RAG) turns that sprawl into precise, cited responses. Instead of asking a model to “remember” everything, you teach it to look up the right fragment at the right time and then compose an answer that follows your rules.
This article is a practical field guide for marketers: what RAG is (in plain language), when to use it, how to wire it to your stack, and how to measure impact without risking data or brand safety.
What RAG actually does (and why it matters for marketing)
Without RAG: the model guesses from general knowledge. You get fast drafts, but facts drift, claims lack sources, and brand voice is inconsistent.
With RAG: the model first retrieves relevant passages from your approved corpus (brand canon, SOPs, case studies, KPI dictionary), then generates a response that cites those sources and conforms to your policies. You get:
- Answers that match your product reality and tone.
- Citations to show “where this came from.”
- Lower risk of invented numbers or non-compliant claims.
Think of RAG as a librarian + copy chief. It finds the right page, then writes to spec.
When to use RAG vs fine-tuning vs “prompt-only”
- Prompt-only: good for ideation or style transformations when factual accuracy doesn’t matter (e.g., “brainstorm headlines”).
- RAG: best when accuracy, policy, and currency matter (e.g., reporting notes, product claims, UTM rules, FAQ answers).
- Fine-tuning: useful for style regularity at scale, but not a substitute for retrieval; you still want live facts and citations.
Most marketing teams win with RAG-first plus a light style fine-tune later.
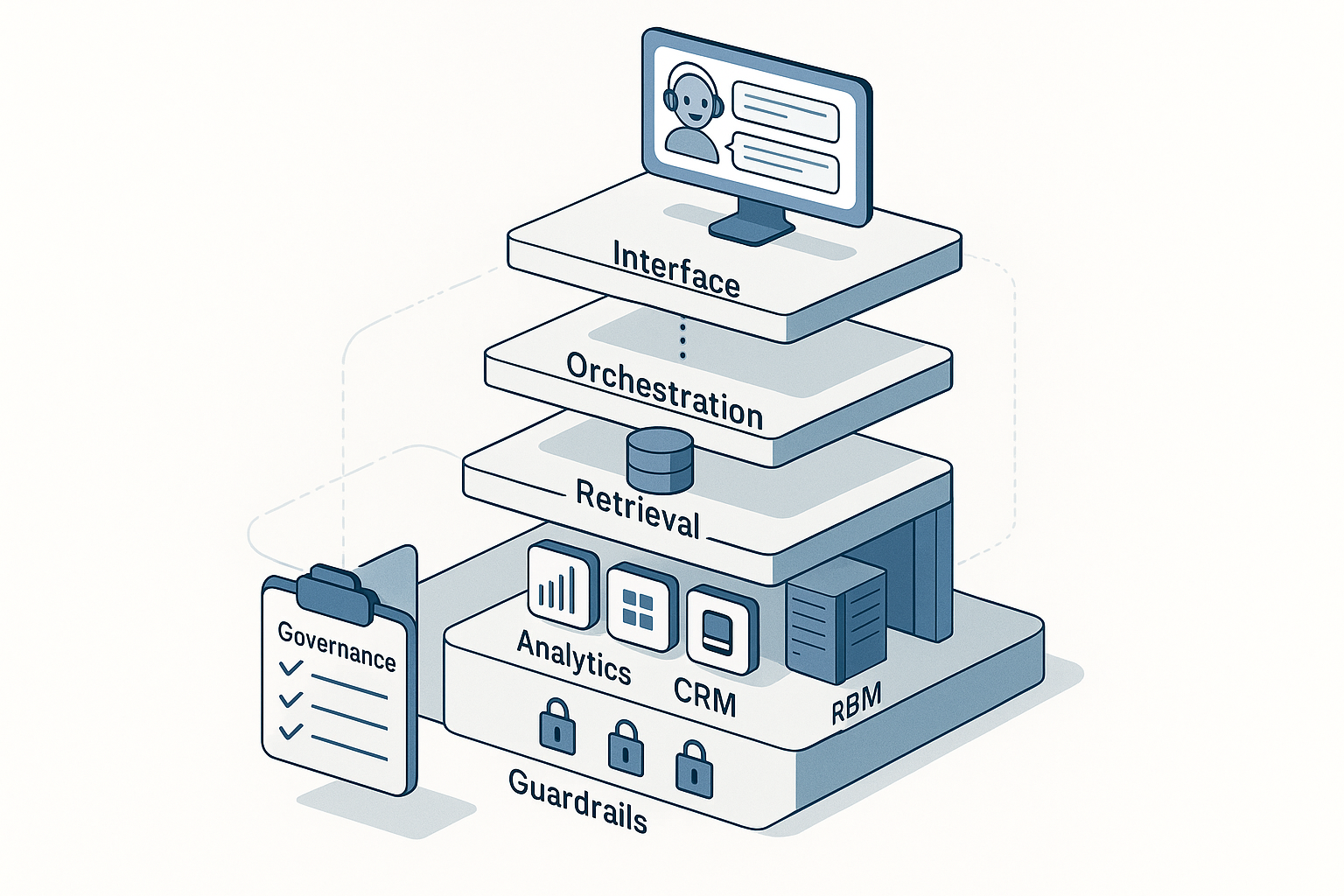
The marketer’s RAG architecture (vendor-agnostic)
- Corpora (your “canons”)
- Brand Canon: voice & tone, message architecture, positioning, approved claims.
- Performance Canon: KPI dictionary, dashboard definitions, naming conventions, post-mortems.
- Ops Canon: SOPs for briefs, UTM/GA4 rules, QA checklists, accessibility/legal footers.
- Public Canon: website/product pages, press, case studies that you’re comfortable citing.
- Ingestion & indexing
- Normalize to text/HTML; remove boilerplate.
- Chunk by meaning (200–800 tokens). Add metadata: source, owner, version, sensitivity, locale, product, funnel stage.
- Build allowlists/denylists; exclude PII/finance unless redacted.
- Retrieval
- Hybrid search (dense + keyword + metadata filters).
- Rerank top passages for semantic relevance.
- Return 3–8 passages with source cards (title, URL, last-reviewed date).
- Generation with guardrails
- System prompt encodes policy: “never invent numbers,” “cite sources inline,” “follow Brand Canon vX,” “no legal advice—insert disclaimer.”
- Output scanner catches PII, risky claims, broken UTMs.
- Delivery
- Chat in Slack/web with sidebar citations.
- One-click export to Docs, CMS/MRM, or Jira (read-only writes until governance is proven).
Data you should (and shouldn’t) index first
Start with
- Brand voice rules, positioning, and message maps.
- KPI definitions & dashboard glossaries.
- SOPs and checklists (briefs, QA, accessibility, UTM, release).
- Case studies and product sheets you already publish.
Gate or redact
- CRM notes, support transcripts, any PII/PHI/PCI.
- Draft legal contracts or confidential pricing annexes.
- Unreviewed experiments and internal hot-takes.
RAG amplifies whatever you feed it—curate before you index.
High-impact RAG use cases for marketing
- SOP Q&A
“What are our UTM rules for webinars?” → Returns the exact rule, examples, and a copy-paste template with correct case and separators. - Brief Builder
“Draft a paid social brief for Product X (EU market).” → Pulls audience JTBD, positioning, proof points, legal lines; outputs message map, creative checklist, and approved claims with citations. - Content QA with Citations
Paste copy → flags off-brand words, missing disclaimers, claim mismatches; proposes a diff with sources. - Board-ready reporting notes
“Summarize last week’s search.” → Explains drivers vs benchmarks, calls out anomalies, and includes metric definitions and dashboard links. - Competitor quick-scans
Ingest public pages → returns a side-by-side on claims, pricing posture, proof types, with what you can say in response per Brand Canon.
Answer shaping: from snippets to trustworthy outputs
Rules that reduce rework
- Cite every fact that isn’t common knowledge.
- Prefer quotes from your canons for sensitive lines (claims, legal).
- Use controlled glossaries for metrics and naming conventions.
- Require a “confidence & coverage” footer: what was cited, what was missing.
Example answer template
Answer
— short structured response
Sources
— Canon title (v3.1), section, last reviewed date
— Dashboard dictionary: “CPA” (link)
Gaps
— No current EU pricing sheet in canon; used US sheet v2.2. Mark as LOW confidence.
Implementation, step by step (30/60/90)
Days 1–30: Foundation
- Pick 2 use cases (SOP Q&A + Content QA).
- Stand up private endpoints, SSO, logging.
- Curate and index the four canons with metadata.
- Write system prompt and blocked terms list.
- Create 30–50 “golden questions” and reference answers.
Days 31–60: Pilot
- Roll to 8–12 power users.
- Add analytics warehouse (read-only) for metric definitions and trend snippets.
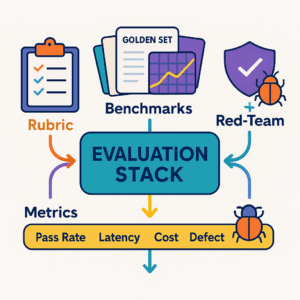
- Build the evaluation harness: automated runs of the golden set after each change; score on factuality, policy adherence, tone, usefulness.
Days 61–90: Scale
- Expand RBAC, add role-specific prompts (e.g., Analyst vs Copywriter).
- Introduce caching and smaller models for classify/extract steps.
- Publish SOPs: prompt hygiene, HIL review, incident response.
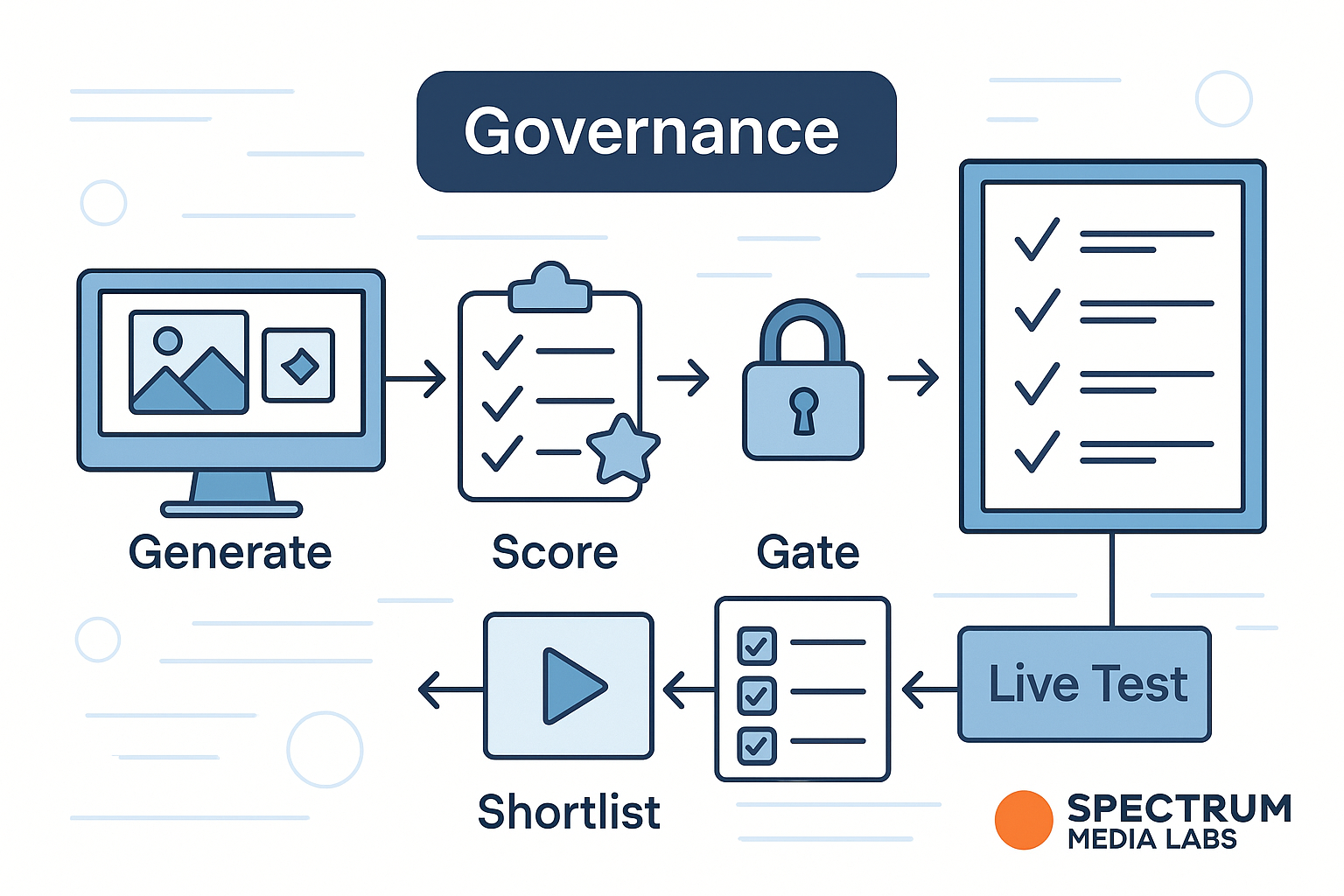
Evaluation: how to know it works
Score each answer 1–5 on:
- Grounding: all non-obvious claims cite sources; no contradictions.
- Policy compliance: tone, brand words, disclaimers.
- Usefulness: does this actually unblock the task?
- Format: uses your templates (brief, diff, report note).
- Latency & cost: stays within budgets.
Track weekly:
- Time to first draft (brief, note, FAQ).
- % answers with complete citations.
- Edit count per asset after QA.
- Red-team pass rate (hallucination/PII tests).
- Tokens per resolved task; cache hit rate.
Cost control without degrading quality
- Chunk smaller, retrieve fewer (3–5 great chunks > 12 mediocre).
- Hybrid search + rerank to avoid wasting tokens on irrelevant passages.
- Cache final answers to recurring questions (e.g., style or KPI definitions).
- Route classification/extraction to small models; generation to a strong one.
- Compress context (extract structured fields from long PDFs into short fact cards).
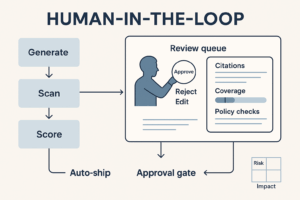
Guardrails & governance that marketers actually need
- System policy: no invented numbers, cite sources inline, use product names exactly as in the glossary, never speculate on legal/medical topics.
- Output filters: NER/regex to block PII, competitor confidentials, embargoed terms.
- Audit logs: user ID, tools touched, corpora accessed, latency, version.
- Review workflows: legal copy goes through “Submit for review” with sources pre-attached.
- Change management: version every canon and publish release notes; re-run the golden set after updates.
Practical prompt + retrieval patterns
System prompt (essentials)
You are Spectrum’s policy-aware assistant.
- Use Brand Canon v3.2 and KPI Dictionary v2.1.
- Cite sources after each non-obvious claim: [Canon vX, section].
- No invented numbers. If a fact is not in the retrieved context, say so and suggest where to find it.
- Follow house style (short paragraphs, concrete verbs).
- For metrics, always link the definition in the dictionary.
User prompt
Draft a paid social brief for Product X (EU).
Include audience JTBD, message map, value proof, creative checklist, UTMs per UTM Rules v2.4.
Retrieval query construction
- Expand user terms using your controlled vocabulary (e.g., “paid social” → “Meta, Ads, CPM”).
- Filter:
canon:brand OR canon:opsANDlocale:EUANDversion:latest. - Boost recent post-mortems and top-performing case studies.
Pitfalls (and fixes)
- Over-chunking: tiny fragments lose context → keep complete rules/claims in one chunk with headings.
- Indexing junk: drafts and outdated PDFs pollute answers → enforce an allowlist with owners and review dates.
- “Just add more data”: quality beats quantity—start with the four canons and expand deliberately.
- No human loop: for public copy, require sign-off until your evals show stability.
What success looks like in 90 days
- Brief creation time down 50–70%; first-pass QA pass rate up 30%+.
- 95% of answers include correct citations; zero critical policy violations.
- Teams open the bot to check rules, not to argue about them.
- Finance sees predictable spend per resolved task with a rising cache hit rate.
Conclusion
RAG isn’t a research paper trick—it’s a production pattern that makes AI shippable for marketing. Start with curated canons, wire retrieval with metadata filters, encode your rules in the system prompt, and judge everything with an evaluation harness. When answers are grounded and cited, trust (and throughput) follow.

Add comment