
Most teams treat prompts like magic spells: someone pastes a long incantation into a chat box and hopes for the best. That scales about as well as tribal knowledge. If you want repeatable results across channels and people, you don’t need “a great prompt.” You need a prompt system: task-specific templates, typed variables, canonical sources, and guardrails—wrapped in versioning and evaluation like any other production asset.
This playbook shows how to build that system so outputs are consistent, compliant, and fast.
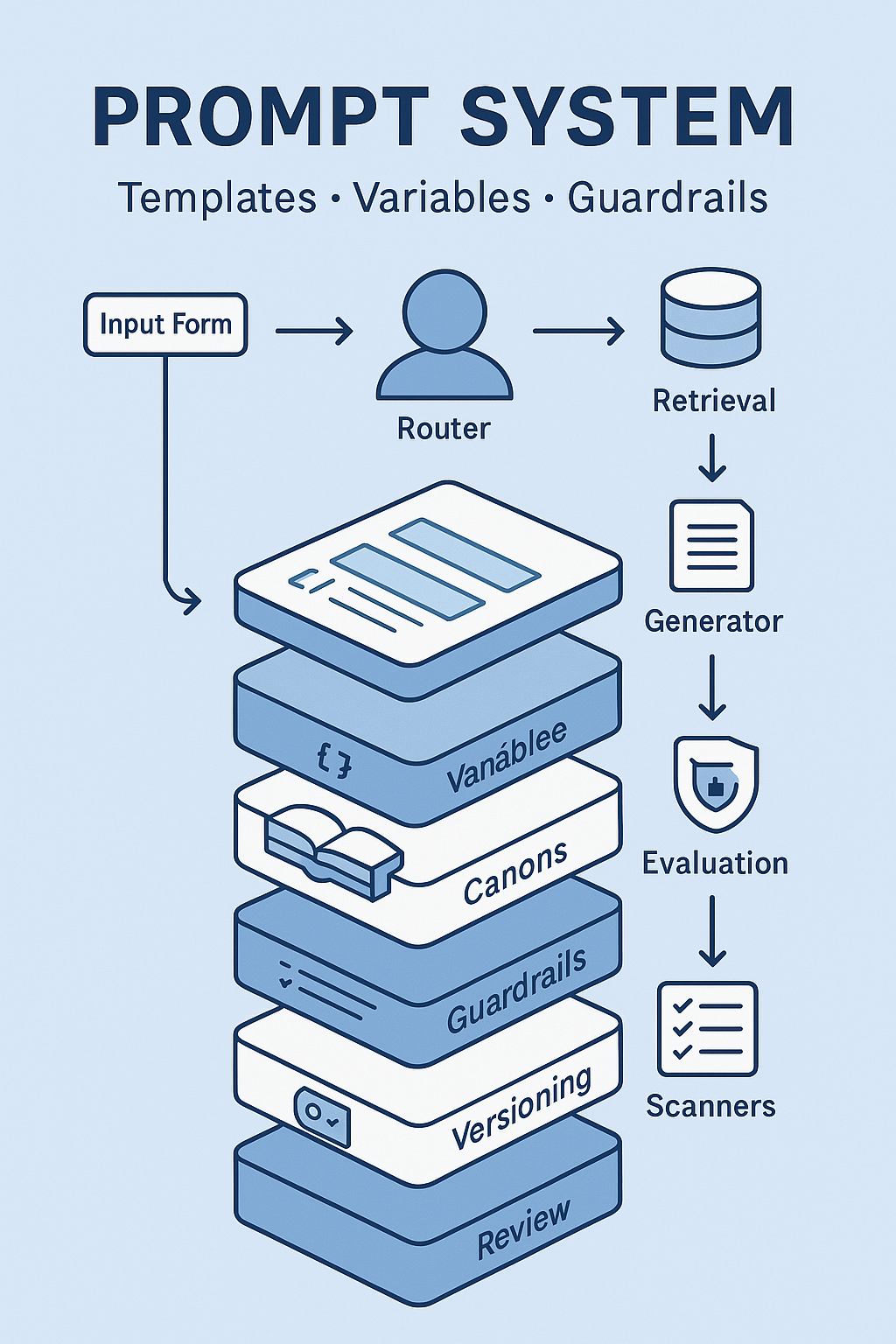
What is a “prompt system”?
A prompt system is a small stack:
- Template — a task recipe (inputs → required sections → tone → constraints).
- Variables — typed, validated fields that the template expects.
- Canons — approved sources (brand, claims, KPI dictionary, SOPs) the model must cite.
- Guardrails — rules and filters (blocked terms, claim matcher, PII scanner, disclaimers).
- Evaluation — golden tests + scoring rubric to prevent drift.
- Versioning & release — changes are PR’d, reviewed, and shipped with notes.
Think “design system,” but for language and analysis.
Core principles
- Single-purpose templates beat generalist mega-prompts.
- Inputs are data, not prose. Use forms or YAML/JSON, not free-text.
- Every non-obvious fact needs a source. Retrieval first, then generate.
- Policy lives in the system prompt (and output filters), not in people’s heads.
- Ship read-only first. Add API writes only after evals are stable.
The anatomy of a production template
Below is a real, vendor-agnostic pattern you can copy.
# templates/brief_builder.yaml
meta:
id: brief_builder_v3.2
owner: marketing_ops@spectrum
purpose: "Create a campaign brief from Brand/Performance Canons"
outputs: [message_map, audience_jtbd, proof, checklist, UTMs, risks]
system:
role: "Policy-aware assistant for Spectrum"
policies:
- "No invented numbers. Cite canon sections for all claims."
- "Use Brand Canon v3.1 tone rules."
- "For metrics, link dictionary entries."
- "Add legal disclaimer §2.4 for health claims."
inputs:
product_name: {type: string, required: true}
markets: {type: list[string], allowed: ["US","UK","EU","CA"], required: true}
goal: {type: enum, values: ["awareness","lead_gen","sales"], required: true}
persona_id: {type: ref, source: data/personas.csv, required: true}
offer: {type: string, required: true}
constraints: {type: list[string], required: false}
retrieval:
corpora: ["brand_canon", "performance_canon", "legal_canon", "case_studies_public"]
filters: {locale: "{{ markets }}", version: "latest"}
sections:
- heading: "Context"
- heading: "Audience (JTBD)"
- heading: "Message Map"
- heading: "Proof & Citations"
- heading: "Creative Checklist"
- heading: "UTM Plan (Rules v2.4)"
- heading: "Risks & Mitigations"
formatting:
style: "short paragraphs, active voice, concrete verbs"
citations: "inline in [Canon vX, §Y] format with links"
Why this works
- The meta block makes the asset traceable.
- system.policies codify behavior once for everyone.
- inputs are typed and validated by a form or CLI; no guessing.
- retrieval forces grounded answers with citations.
- sections lock in structure so stakeholders know where to look.
Variables: treat them like an API
Create a schema for each template and validate on submit. Example for a reporting note:
# inputs/reporting_note.example.yaml
date_range: {start: 2025-09-23, end: 2025-09-29}
channels: ["search","social"]
primary_metric: "cost_per_acquisition"
benchmarks: {search: "L4W", social: "L8W"}
stakeholder: "CFO"
If a variable is missing or invalid, the runner fails before calling the model.
Tips
- Prefer enums and references (e.g., persona IDs) over free text.
- Keep optional fields truly optional—don’t hide required context behind prose.
- For multi-market work, expand variables (locale, currency, disclaimers) automatically.
Guardrails that save you rework
- System policy
- No invented numbers, no legal advice, no PII.
- Use glossary names exactly; forbid banned phrases.
- Retrieval & citations
- Answers must include source cards with version and review date.
- If a fact isn’t found, the template must state the gap.
- Output scanners
- Claim matcher: verifies lines against the approved claims library.
- PII/regex: blocks emails, phones, MRNs, etc.
- Accessibility: checks contrast ratios and alt-text when generating visual copy.
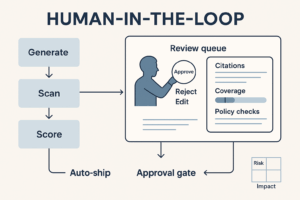
- Human in the loop
- Public copy routes to Legal/Brand; internal notes can auto-ship with citations.
A minimal “router” for runtime
- Classify the user intent → pick a template.
- Validate inputs against the schema.
- Retrieve chunks from canons with metadata filters.
- Run generation with the system policies.
- Scan outputs; attach citations; compute confidence.
- If public-facing → send to reviewer; else → deliver.
Example: three high-value templates
1) Reporting Note (board-ready, 200–250 words)
Inputs: date_range, channels, primary_metric, stakeholder.
Rules: define metrics from the KPI dictionary first; add “drivers, anomalies, next steps”; avoid adjectives.
Guardrails: forbid absolute claims without denominators; require links to dashboards.
2) Content QA (diff style)
Inputs: raw_copy, target_market, claim_set.
Rules: flag off-brand words, broken UTMs, missing disclaimers; return a unified diff.
Guardrails: claim matcher + accessibility check; red-flag non-citable facts.
3) Brief Builder (multi-market)
Inputs: product_name, markets, goal, persona_id, offer.
Rules: produce message map, JTBD, proof, checklist, UTMs; separate local disclaimers by market.
Guardrails: block unapproved superlatives; require at least two case-study citations.
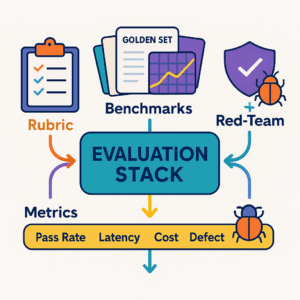
Evaluation: prevent prompt drift
Create a golden set of 30–100 tasks per template with reference outputs and a rubric:
- Grounding (0–2) — Are all non-obvious claims cited?
- Policy (0–2) — Banned terms? Correct disclaimers?
- Usefulness (0–2) — Does it unblock the task?
- Format (0–2) — Sections, length, links present?
- Tone (0–2) — Brand voice match?
Run the suite on every change. Block releases that score <8/10 or fail any must-pass rule (e.g., missing citations).
Versioning & release notes
Store everything (templates, schemas, policies, tests) in Git:
/promptpacks
/brief_builder
template.yaml
schema.yaml
guardrails.yaml
tests.jsonl
CHANGELOG.md
Release like code:
- PR → CI runs golden set → reviewers approve → tag
brief_builder_v3.2. - Publish CHANGELOG.md so writers and analysts know what changed.
Metrics that matter
- Time to first draft (target −50–70%).
- Edit count per asset (target −30%+).
- Citation completeness (% of answers with valid sources, target 95%+).
- Policy violations caught (should drop over time).
- Cost per resolved task (tokens + time).
- Adoption (active users per week, tasks per template).
Anti-patterns to avoid
- One prompt to rule them all. You’ll get averages, not outcomes.
- Free-text inputs. Guaranteed drift and rework.
- “We’ll remember that.” Models don’t—persist policies and canons.
- Skipping evals. If it isn’t tested, it will regress.
- Copy-paste templates in Notion. Use a single source of truth with versioning.
Quick start (10 steps)
- List your top 3 recurring tasks (e.g., reporting note, brief, QA).
- Draft one template per task.
- Define input schemas (typed, validated).
- Build/clean your Brand/Performance/Legal Canons.
- Add system policies + blocked terms.
- Wire retrieval with metadata filters.
- Add scanners (claims, PII, accessibility).
- Create a 30–50 item golden set per template.
- Ship to 8–12 power users; measure time saved and edit rate.
- Assign an owner; publish release notes monthly.
FAQ
Do we still need “prompt engineering”?
You need template engineering—designing task recipes, schemas, and policies. It’s more operations than poetry.
Where should templates live—tooling or docs?
In a repository with CI and owners. Docs can mirror, but the repo is the truth.
Can we fine-tune instead?
Fine-tuning helps with style consistency. It doesn’t replace retrieval, policies, or schemas.
How do we keep costs down?
Validate inputs, retrieve fewer/better chunks, route classify/extract steps to smaller models, cache recurring answers.
Conclusion
Prompts don’t scale. Prompt systems do. When you ship templates with typed inputs, grounded retrieval, and guardrails—plus evaluation and versioning—you turn AI from a clever assistant into an operational capability. Your outputs get faster, safer, and more consistent. Your team stops arguing about wording and starts shipping.

Add comment