
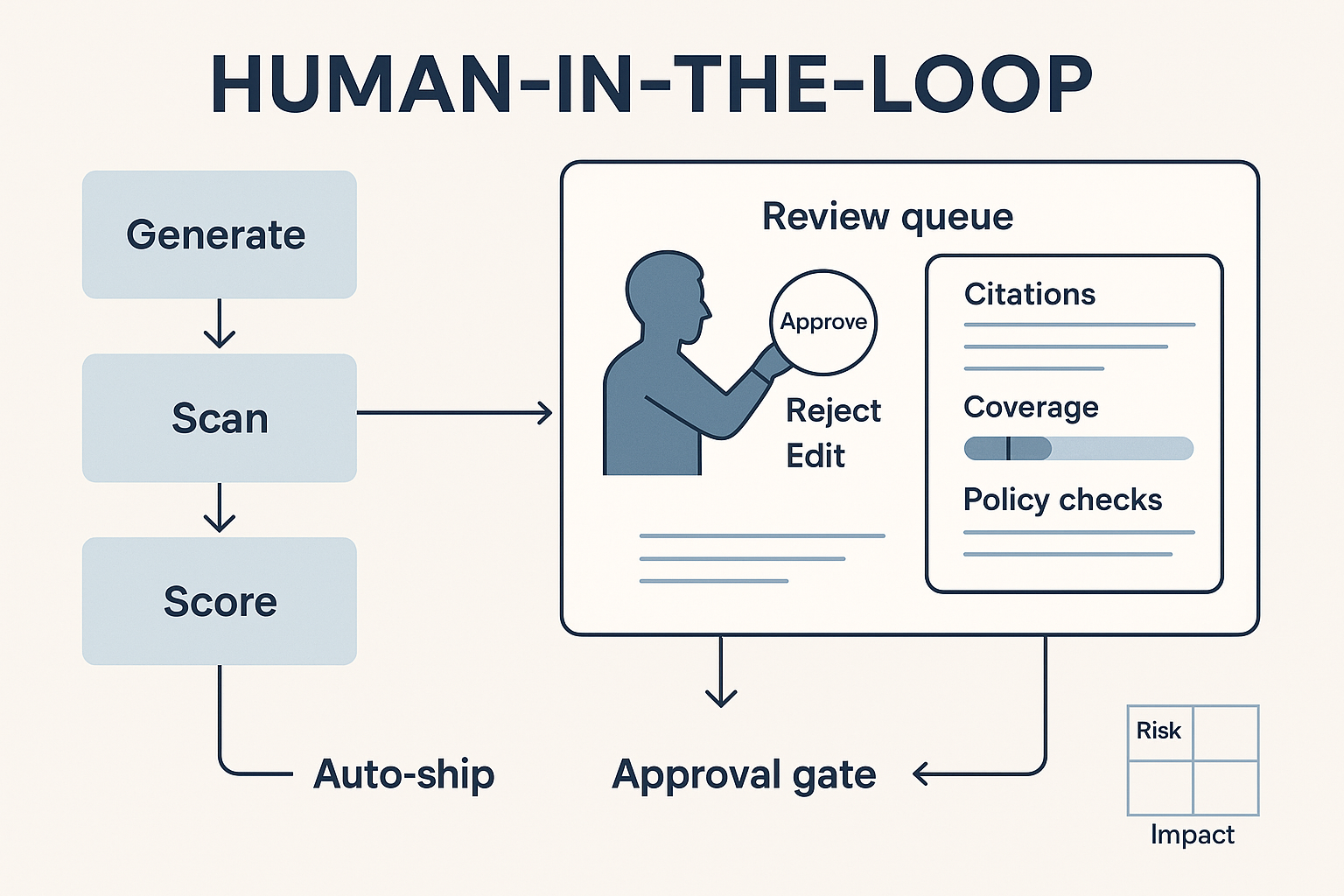
Automation is wonderful at speed, consistency, and recall—but terrible at judgment. If you want outputs that are not only fast but defensible, you need Human-in-the-Loop (HITL): explicit checkpoints where people design, supervise, and sign off on automated work. HITL isn’t a “nice to have.” It’s the control surface that lets leadership sleep at night.
This guide shows where to put humans, what they should do, and how to measure whether the loop is actually raising quality rather than slowing teams down.
What “Human-in-the-Loop” really means
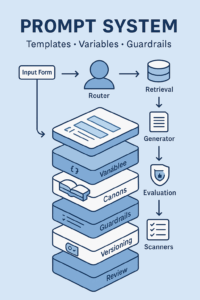
HITL is not “someone glances at it.” It’s a designed workflow with:
- Gates: moments when work cannot proceed without human approval.
- Policies: what must be checked (citations, claims, tone, accessibility, legal lines).
- Evidence: what the system must show (sources, diffs, confidence/coverage).
- Authority: who can approve, who can override, and what is auto-rejected.
- Telemetry: logs that prove what happened and why.
Think “code review,” but for language, analysis, and creative.
Where humans add the most value
Design-time (before any runs)
- Define templates and typed inputs; choose allowed data sources.
- Write system policies (“no invented numbers,” “cite canon sections,” “add market disclaimers”).
- Curate canons (Brand, Performance, Legal) and remove risky data.
Run-time (during generation)
- Approve low-confidence or low-coverage answers.
- Resolve conflicts when sources disagree.
- Make taste and risk calls (edginess vs brand posture).
Post-release (after shipping)
- Audit incidents, update policies, and add new golden tests.
- Review drift reports (tone, claims, platform rules).
Risk-based HITL: decide when to block, sample, or auto-ship
Use a Risk × Impact matrix to set the level of human review:
| Impact \ Risk | Low risk | Medium risk | High risk |
|---|---|---|---|
| Internal only (notes, drafts) | Auto-ship with logging | Auto-ship + 10% random sampling | Approval gate |
| Limited external (email to list, blog) | Sample 20% | Approval gate | Approval + Legal |
| High-stakes external (paid ads, pricing, claims) | Approval gate | Approval + Legal | Block unless manually authored |
Trigger gates automatically when any of these are true:
- Confidence < threshold or coverage (cited context) < threshold.
- Facts without citations.
- Use of restricted terms or sensitive topics.
- New markets/locales with untested policies.
Evidence the system must present to reviewers
Reviewers shouldn’t hunt. Require a single, compact review panel containing:
- Sources with version and last-reviewed date.
- Diff view (what changed vs the writer’s draft).
- Policy checks (claims, disclaimers, accessibility, UTMs).
- Confidence & coverage meter (how much was grounded vs guessed).
- Cost & latency (helps ops tune budgets without guessing).
- One-click actions: Accept • Edit • Reject • Request re-run (with reason).
Playbooks by marketing task
1) Creative copy (public)
- Gate: Creative Lead approval; Legal if claims appear.
- Checks: banned terms, claim matcher, market disclaimers, accessibility (contrast, alt text).
- Evidence: citations to Brand/Legal Canons + case studies.
- Override: Creative Lead can keep deliberate tension (must add rationale).
2) Reporting notes to executives
- Gate: Analyst approval when coverage < 90% or anomalies are flagged.
- Checks: KPI dictionary links, denominator sanity (rates vs counts), timeframe alignment.
- Evidence: dashboard links + metric definitions.
- Override: Require a note if an assertion relies on judgment.
3) Knowledge-base answers (SOP Q&A)
- Gate: Auto-ship with weekly random sampling; approval if policy fails.
- Checks: SOP version match, locale rules, escalation paths.
- Evidence: specific SOP section anchors.
4) Ad variants & thumbnails
- Gate: Brand approval + Legal for regulated categories.
- Checks: platform specs, text-in-image ratio, visual accessibility, claim wording.
- Evidence: spec checklist and policy pass/fail summary.
The mechanics: how to embed HITL without bogging down
- Queues, not pings. Route items to a review queue with SLAs (e.g., 4 business hours).
- Batching. Reviewers process similar assets together to reduce context switching.
- Role-aware views. Legal sees claims & disclaimers first; Creative sees tone & rhythm first.
- Escalation. If an item sits idle beyond SLA, auto-reassign or escalate to a backup reviewer.
- Logging by default. Every approval captures “who/when/why,” linked to the specific model + policy version.
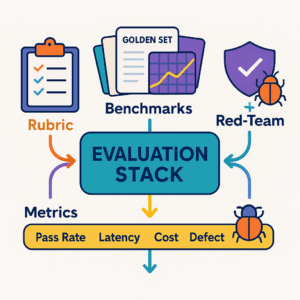
Evaluation: prove the loop makes things better
Maintain a golden set of 50–200 tasks per template. On each release:
- Run the full set and score on Grounding, Policy, Usefulness, Format, Tone (0–2 each).
- Block release if score < 8/10 or any must-pass rule fails (e.g., missing citations).
- Track live metrics weekly:
- Approval pass rate and average review latency
- Edits per asset before sign-off
- Incidents (post-launch pulls, policy breaches)
- Random-sample defect rate on auto-shipped items
- Cost per resolved task (tokens + human minutes)
When defects cluster, add them to the golden set and update policies.
HITL UI copy you can steal
- Banner: “Grounded in 3 sources · Coverage 84% · 1 policy alert”
- Decision buttons: Accept • Edit • Reject • Request Re-run
- Rationale field (required on Reject/Override): “What risk are we accepting or avoiding?”
- Footer: “Model v5.3 · Policy v3.1 · Canon Brand v3.4, Legal v2.2 · Trace ID #A7F3”
Incident response (when something slips)
- Pull & notify (what, where, when, audience reached).
- Triage severity (S1 legal/compliance, S2 brand risk, S3 minor).
- Containment (remove asset, pause automation on that template/market).
- Root cause (policy gap, retrieval miss, reviewer error, model drift).
- Corrective actions (new rule, added test, retraining, role reminder).
- Post-mortem shared to stakeholders within 3 business days.
30/60/90 rollout
Days 1–30 — Foundation
- Map tasks to risk levels; define gates and owners.
- Ship review queue with diff + citations + coverage.
- Stand up golden tests; log everything.
Days 31–60 — Pilot
- Run 3 cycles on one product line (copy, reporting, SOP Q&A).
- Measure review latency, pass rate, defect rate in random samples.
- Add automatic triggers (low coverage, sensitive terms, new locales).
Days 61–90 — Scale
- Expand to paid media + thumbnails; add Legal sub-queue.
- Publish SOPs and SLAs; automate weekly QA reports.
- Tie approval rights to RBAC; add backup reviewers and escalation rules.
Quick checklists
Reviewer checklist (public copy)
- All non-obvious claims cite canon/case study
- Market disclaimers present
- Accessibility passes (contrast, alt text)
- Voice is on-brand OR “deliberate tension” documented
- UTMs and naming conventions verified
Ops checklist (system health)
- Golden set run after each policy/model change
- Random sample audited weekly
- Incidents reviewed and tests updated
- Coverage thresholds tuned per template/market
Conclusion
You can’t outsource judgment. What you can do is instrument it: make the human parts explicit, measurable, and efficient. With clear gates, evidence, authority, and telemetry, automation stops being a black box and starts being a dependable teammate. That’s how you ship faster and safer—without sanding the edge off your work.

Add comment