

AI “agents” are creeping from demos into ad accounts. Some teams already let software propose budgets, rotate creatives, and pause losers overnight. Others are rightly cautious: platform auctions are noisy, attribution is messy, and it’s easy to automate yourself into expensive mistakes. This guide cuts through the hype—what agentic systems actually do in media buying, the math underneath, the myths to avoid, and a vendor-agnostic setup you can ship without gambling the quarter.
What an agent is (in plain English)
An agent is a loop with four parts:
- Perceive: read state (spend, CPA, ROAS, pacing, learning phase flags, creative fatigue, inventory signals).
- Decide: choose an action (shift budgets, adjust bids/targets, rotate creative, open/close experiments).
- Act: call platform APIs (or prepare human-approved changes).
- Learn: compare expected vs actual results; update beliefs and policies.
It’s not a magic bidder. It’s a disciplined policy that repeats every N minutes/hours within constraints you set.
What agents are good at vs what they are not
Strong fits
- Pacing & drift correction: keep daily spend and CPA within bands; detect sudden CPC jumps and pull back.
- Variant allocation: move impressions toward higher predicted value creatives while preserving exploration.
- Guardrail enforcement: stop words, geo blocks, frequency caps, audience exclusions, budget ceilings.
- Hygiene at scale: kill obvious 0-click placements, fix UTMs, re-pin disapproved assets after edits.
Weak fits
- Brand judgment: tone, taste, edge cases in claims.
- Strategy selection: which product to promote this quarter, how to price an offer, what narrative to push.
- Attribution arbitration: deciding whether ads or lifecycle drove the sale when signals conflict.
Keep humans on narrative, claims, and cross-channel strategy. Use agents for repeatable optimization under constraints.
The science (light but useful)
Media buying with agents is mostly contextual bandits + pacing control + rules.
- Exploration vs exploitation: Algorithms like Thompson Sampling or UCB help allocate impressions among creatives/audiences while continuously testing. You’ll want minimal exploration rates (e.g., 5–20%) so new ideas don’t starve.
- Credit assignment: Don’t rely on last-click. Use a stable proxy label (e.g., modeled conversion probability in 7 days, or qualified lead score) that’s consistent even when cookies/signals vary.
- Non-stationarity: Auctions shift hourly. Add decay to recent data (yesterday weighs more than last week) and detect regime changes (CPC jump, inventory change, seasonality).
- Risk constraints: Treat CPA/ROAS targets as soft bounds with penalties. Your policy is maximizing reward subject to cost and brand safety constraints, not chasing extremes.
You don’t need to implement RL from scratch. You do need to encode these principles into your agent’s policy and evaluation.
Myths to ignore
- “The platform already optimizes—agents can’t add value.” Platforms optimize within a campaign. Agents operate across campaigns and channels, enforce your house rules, and keep experimentation honest.
- “Just give the agent a single ROAS target.” One number hides risk. Use multi-objective policies: CPA/ROAS, spend pacing, exploration minimums, saturation/overlap, and safety gates.
- “Full automation or nothing.” Use HITL (Human-in-the-Loop) for high-impact actions (budget moves > X%, bids on regulated categories, geo changes).
- “More data fixes everything.” Bad labels (dirty conversions, double-counted events) will mislead any policy. Clean the event stream first.
Pre-flight checklist (don’t skip)
- Signals: server-side conversions / CAPI, deduping, clear primary conversion, and a quality proxy (e.g., SQL, qualified demo).
- KPI dictionary: unambiguous formulas for CPA, MER, assisted conversions, view-through rules.
- Taxonomy: campaign naming, UTMs, product/feed hygiene.
- Guardrails: forbidden terms, max bids, geo & placement blocks, frequency caps, budget ceilings.
- Creative supply: at least 6–12 distinct concepts in rotation; metadata (hook, format, claim) for learning.
- Sandbox: a dev account or read-only dry-run mode for the agent.
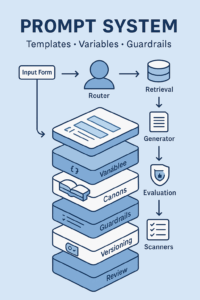
A practical agent policy (vendor-agnostic)
State observed (hourly/4-hourly):
- Spend vs daily pace, CPA/ROAS vs band, learning phase flags.
- Creative performance (ctr, cvr, est. value), fatigue markers.
- Auction signals: CPC shift, CPM floor movement, delivery health.
- Constraint status: frequency, geo, placement, approval.
Actions:
- Budget ±X% per campaign/adset (bounded by daily caps).
- Exploration guarantee: keep ≥E% of spend on new/under-tested variants.
- Pause/rotate creatives by rule (e.g., N impressions with p95 below control).
- Open/close experiments (A/B or holdouts) with pre-registered analysis.
- Escalate to human when crossing risk thresholds.
Guardrails (blocking):
- CPA/ROAS outside band for Y hours.
- Uncited/forbidden claims in creative text (scanner).
- Disapproved assets; unsafe placements; geo anomalies.
- Budget change > MaxDelta or cumulative change > DailyDelta.
Confidence & coverage:
- Every recommendation ships with confidence (data volume, variance) and coverage (percent grounded in recent samples). Low-confidence actions require human approval.
Sample config (YAML)
policy:
objectives:
- name: cpa
target: 65
band: [55, 75]
weight: 0.5
- name: roas
target: 2.5
band: [2.0, 3.2]
weight: 0.4
- name: exploration_rate
min: 0.12
weight: 0.1
pacing:
daily_spend: {target: 25_000, band: [0.9, 1.1]}
check_interval_minutes: 120
actions:
max_budget_change_pct: 20
escalate_change_pct: 10
safety:
blocked_terms: ["#1", "guarantee", "cure"]
placements_blocklist: ["in_app_gambling", "juvenile_content"]
freq_cap_per_day: 3
eval:
backtest_window_days: 28
guard_thresholds: {confidence_min: 0.6, coverage_min: 0.8}
Experiment design the agent can run
- Creative multi-armed bandits: 6–12 variants; agent ensures min exploration and uses Bayesian posteriors to reallocate.
- Budget rebalancing tests: 70/30 holdout across two campaigns to estimate diminishing returns.
- Bid/goal sweeps: controlled changes to target CPA/ROAS to map efficient frontier.
- Audience overlap sweeps: rotate inclusions/exclusions to reduce cannibalization.
- Landing page splits: hand off to CRO stack; agent reads conversion rate deltas as a feature.
Pre-register hypotheses, stop rules, and decision criteria so wins are credible.
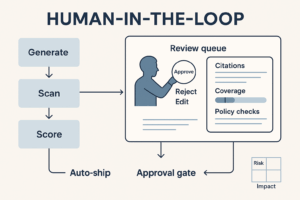
HITL: where humans approve
- High-impact moves: budget deltas > 10% at once, geo changes, new placements.
- Regulated categories/claims: health/financial language; legal must approve.
- Narrative/brand: when the agent proposes claim shifts or creative rewrites, route to Brand.
- Low coverage/low confidence: data too thin or variance too high.
Reviewers get a compact panel: proposed action → expected effect → confidence/coverage → citations/logs → Accept/Reject/Edit.
Evaluation & dashboards that matter
Track weekly by channel and campaign:
- Pacing hit rate: % hours within spend band.
- Risk events caught: count + time to mitigation.
- Exploration achieved: share of spend on new variants.
- Lift vs human baseline: CPA/ROAS delta vs last 4 weeks pre-agent.
- Learning efficiency: time to detect fatigue; time to ramp winners.
- Cost to decide: tokens/compute + human minutes per approved change.
Run a golden set of replayed weeks (backtests) on each policy update. Block release if CPA variance spikes or guardrail defects increase.
Failure modes (and fixes)
- Dirty labels: duplicate or late conversions inflate learning. Fix: dedupe at the edge; use a stable proxy like qualified lead score.
- Over-fitting to short windows: oscillations. Fix: add decay but keep a minimum horizon; smooth with hierarchical priors.
- Exploration starvation: new creatives never get a chance. Fix: enforce exploration floors, not just “best wins.”
- Policy bypass via copy: aggressive claims slip in. Fix: claim matcher + legal gate for public copy.
- Attribution whiplash: paid vs lifecycle fights. Fix: evaluate on a channel-agnostic KPI (MER, blended CPA) for macro decisions; use model-specific metrics for micro moves.
30/60/90 rollout
Days 1–30 — Foundation
- Clean events & KPIs; wire server-side conversions.
- Define guardrails and YAML policy v1; dry-run in read-only mode with alerts only.
- Build dashboards: pacing, exploration, CPA bands, risk events.
Days 31–60 — Pilot
- Turn on recommend-only for one account (search or paid social).
- Add HITL queue; approve only low-risk actions (≤10% budget shifts, creative rotates).
- Backtest policy updates weekly; tune exploration and decay.
Days 61–90 — Scale
- Expand to second channel; enable auto-apply for low-risk actions; keep HITL for high-impact.
- Add experiment library (budget sweeps, audience overlap tests).
- Publish SOPs, SLAs, and incident playbook; review outcomes with Finance and Brand.
Procurement & compliance notes
- Use private endpoints or vendor settings that disable training on your data.
- Log every action with: who/what/when, model+policy version, expected vs actual outcome.
- Keep a rollback function for budgets/bids to last safe state.
- Document exceptions and map controls to your governance framework.
Conclusion
Agents won’t invent your brand story, but they’re excellent at the boring, high-frequency math of pacing, allocation, and hygiene. Treat media buying as a controlled system: clean signals, explicit guardrails, risk-aware policies, and human checkpoints. Start with read-only, ship a small pilot, and scale as your evaluation shows stability. When the loop is instrumented and governed, agents become force multipliers—not loose cannons.
Add comment